
Archive for the ‘RSE’ Category
I am a co-investigator on an EPSRC-funded grant called the RSE-N (Research Software Engineering Network), the aim of which is to co-ordinate various Research Software Engineering activities nationally. One of the outputs of this work is a ‘State of the Nation’ report which discusses the current state of the national community along with some of its history and the reasons why the concept of ‘Research Software Engineer’ was created back in 2012.
It covers everything that’s happened since the community began. If you want to know more about RSEs, then the report is a good place to start. If you’re making a case for supporting RSEs at your local institution, we hope the report will provide some of the evidence you need.
If you are interested in the RSE movement, I encourage you to read it. https://zenodo.org/record/495360#.WOt5fFMrJE4
UK to launch 6 major HPC centres
Tomorrow, I’ll be attending the launch event for the UK’s new HPC centres and have been asked to deliver a short talk as part of the program. As someone who paddles in the shallow-end of the HPC pool I find this both flattering and more than a little terrifying. What can little-ole-me say to the national HPC glitterati that might be useful?
This blog post is an attempt at gathering my thoughts together for that talk.
The technology gap in research computing
Broadly speaking, my role in academia is to hang out with researchers, compute providers (cloud and HPC) and software vendors in an attempt to be vaguely useful in the area of research software. I’m a Research Software Engineer with a focus on Long Tail Science: The large number of very small research groups who do a huge amount of modern research.
Time and again, what I see can be summarized in this quote by Greg Wilson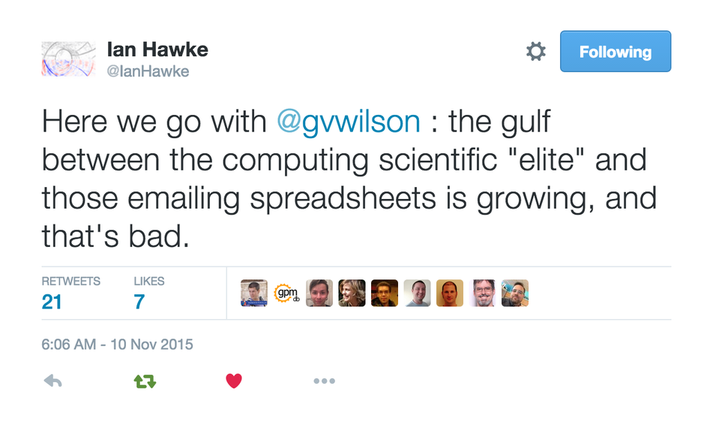
This is very true in the world of High Performance Computing.
Geek Top Gear
I love technology and I love HPC in particular. I love to geek out on Flops, Ghz, SIMD instructions, GPUs, FPGAs…..all that stuff. I help support The University of Sheffield’s local HPC service and worked in Research IT at The University of Manchester for around a decade before moving to Sheffield.
I’ve given and seen many a HPC-related talk in my time and have certainly been guilty of delivering what I now refer to as the ‘Geek Top Gear’ speech. For maximum effect, you need to do it in a Jeremy Clarkson voice and, if you’re feeling really macho, kiss your bicep at the point where you tell the audience how many Petaflops your system can do in Linpack.
*Begin Jeremy Clarkson Impression*
Our new HPC system has got 100,000 of the latest Intel Kaby Lake cores...which is a lot!
Usually running at 2.6Ghz, these cores can turbo-boost to 3.2Ghz for those moments when we need that extra boost of power. Obviously, being Kaby Lake, these cores have all the instruction extensions you’d expect with AVX2, FMA, SSE, ABM and many many other TLAs for all your SIMD needs. Of course every HPC system needs accelerators…..and we have the best of them: Xeon Phis with 68 cores each and NVIDIA GPUs with thousands of tiny little cores will handle every massively parallel job you can throw at them….Easily. We connect these many many cores together with high-speed interconnect fashioned from threads of pure unicorn hair and cool the whole thing with the tears of virigin nerds.
YEEEEEES! Our new HPC system is the best one since the last one and, achieving over a Gajillion Petaflops in the Linpack test (kiss bicep), it will change your life forever.

Any questions?
Audience member 1: What’s a core?
Audience member 2: Why does it run my R script slower than my laptop?
Audience member 3: Do you have Excel installed on it?
There is a huge gap between what many HPC providers like to focus on and what the typical long-tail researcher wants or needs. I propose that the best bridge for this gap is the Research Software Engineer (RSE).
Research Software Engineer as Alpine guide
In my fellowship proposal, I compared the role of a Research Software Engineer to that of an alpine guide:
Technological development in software is more like a cliff-face than a ladder – there are many routes to the top, to a solution. Further, the cliff face is dynamic – constantly and quickly changing as new technologies emerge and decline. Determining which technologies to deploy and how best to deploy them is in itself a specialist domain, with many features of traditional research.
Researchers need empowerment and training to give them confidence with the available equipment and the challenges they face. This role, akin to that of an Alpine guide, involves support, guidance, and load carrying. When optimally performed it results in a researcher who knows what challenges they can attack alone, and where they need appropriate support. Guides can help decide whether to exploit well-trodden paths or explore new possibilities as they navigate through this dynamic environment.
At Sheffield, we have built a pool of these Research Software Engineers to provide exactly this kind of support and it’s working extremely well so far. Not only are we helping individual research groups but we are also using our experiences in the field to help shape the University HPC environment in collaboration with the IT department.
Supercomputing: Irrelevant to many?
“Never bring an anecdote to a data-fight” so the saying goes and all I have from my own experiences are a bucket load of anecdotes, case studies and cursory log-mining experiments that indicate that even those who DO use HPC are not doing so effectively. Fortunately, others have stepped up to the plate and we have survey and interview data on how researchers are using compute resources.
How Do Scientists Develop and Use Scientific Software? is a report on a 2009 survey of 1972 researchers from around the world. They found that “79.9% of the scientists never use scientific software on a supercomputer”
When I first learned of this number, I found it faintly depressing. This technology that I love so much and for which University IT departments dedicate special days to seems to be pretty much irrelevant to the majority of researchers. Could it be that even in an era of big data, machine learning and research software engineering that most people only need a laptop?
Only ever needing a laptop certainly doesn’t fit with what I’ve seen while working in the trenches. Almost every researcher I’ve met who does computational research wishes it was faster or that they had more memory to allow them to do larger problems. Speed is the easiest thing to sell to researchers in the world of RSE. They come for faster execution and leave with a side-order of version control, testing and documentation. A combination of software development and migration to even a small HPC system can easily result in 100x or even 1000x speed-ups for many researchers.
In my experience, it’s not that researchers don’t need HPC, it’s that the jump from their laptop-based workflow to one that makes good use of a HPC system is too large for them to bridge without a little help. Providing that help can result in some great partnerships such as the recent one between the Sheffield RSE group and the Sheffield Faculty of Arts and Humanities.

Want to know how that partnership started? I compiled an experimental R/Rcpp package that they were struggling with and then took them for coffee and said ‘That code took a while to run. Here’s how we can make it go faster….Now…what exactly are you doing because it looks cool?’ Fast forward a year or so and we are on the cusp of starting a great new project that will include traditional HPC and cloud computing as part of their R-based workflow.
My experiences seem to be reflected in the data. In their 2011 article, A Survey of the Practice of Computational Science, Prabhu et al interviewed 114 randomly selected researchers from Princeton University. Princeton have a very strong, well supported HPC centre which provides both resources and the expertise to use them. Even at such a well equipped institution, the authors write that ‘Despite enormous wait times, many scientists run their programs only on desktops’ although they did report much higher HPC usage compared to the Hanny et al survey.
Other salient quotes from the Prabhu interviews include
“only 18% of researchers who optimize code leveraged profiling tools to inform their optimization plans”
“only 7% of researchers leveraged any form of thread based shared memory CPU parallelism”
“Only 11% of researchers utilized loop based parallelism”
“Currently, many researchers fit their scientific models to only a subset of available parameters for faster program runs.”
“Across disciplines, an order of magnitude performance improvement was cited as a requirement for significant changes in research quality”
HPC: There’s plenty of room at the bottom
Potential users of HPC look different to those of 20 years ago. The popularity explosion of languages such as MATLAB, Python and R have democratized programming and the world is awash with inefficient research software. Most of the time, this lack of efficiency is not a problem (see ‘In defense of inefficient scientific code‘) but if a researcher needs to scale up what they are doing, it can become limiting. Researchers might wait for days for the results to come in and limit the scope of their investigations to fit the hardware they have access to — their laptop usually.
The paper of Prabu et al said that an order of magnitude (10x) speed up was cited by researchers as a requirement for significant changes in research quality. For an experienced Research Software Engineer with access to cloud or HPC facilities, a 10x speed-up is usually pretty easy to achieve for this new audience. 100x or even 1000x can be achieved fairly frequently if you employ multiple hardware and software techniques. Compared to squeezing out a few percent more performance from HPC-centric code such as LAPACK or CASTEP, it’s not even all that difficult. I recently sped up one researcher’s MATLAB code by a factor of 800x in a couple of days and I’m a fairly middling developer if I’m brutally honest.
The whole point of High Performance Computing is to accelerate science and right now there is more computational science around than there has ever been before. Furthermore, it’s easier than ever to accelerate! There’s plenty of room at the bottom.
Closing the computational gap with people, training and compute power
The UK’s 6 new HPC centers represent the cutting edge of hardware technology. They provide a crucial component of our national hardware infrastructure, will contribute to research in HPC itself and will doubtless be of huge benefit to computational science. Furthermore, all of the funded proposals include significant engagement with the national Research Software Engineering community – the vital bridge between many researchers and HPC.
Co-development of research software with effort from both RSEs and researchers can be an extremely powerful model. Combine this with further collaboration between RSEs and compute providers and we have an environment that I think is both very exciting and capable of helping to close the rich/poor compute divide.
As an RSE who works with both researchers and University-level HPC providers, I ask for 3 things to be considered by these new regional centres.
- Enjoy your new compute-ferraris. I look forward to seeing how hard you can push them.
- You will be learning new good practice in how to provide HPC services. Disseminate this to those of us running smaller services.
- There’s plenty of room at the bottom! Help us to support the new wave of computational researchers.
Thanks to languages such as MATLAB, Python and R, general purpose programming has been fully democratized. I look forward to working with these new centres to help democratize high performance computing.
One aspect of my EPSRC Research Software Engineering fellowship is to spread basic good practice in research software to different academic fields. Last year, I was invited to participate in a Reproducible research in Ecology workshop which was part of the 2016 International Society of Behavioural Ecology Conference. My contributions included a talk (your research software correct?) and a workshop on using projects and version control using R and RStudio.
The latest output from this stream of work is a paper in Behavioral Ecology called Striving for transparent and credible research: practical guidelines for behavioral ecologists which discusses various topics including preregistration, open science and, of course, research software practices with shout-outs to initiatives such as Software Carpentry, Research Software Engineering and the Software Sustainability Institute. The lead author is Malika Ihle with contributions from Isabel S Winney, Anna Krystalli and me.
The job title ‘Research Software Engineer’ (RSE) wasn’t really a thing until 2012 when the term was invented in a Software Sustainability Institute collaborations workshop. Of course, there were lots of people doing Research Software Engineering before then but we had around 200 different job titles, varying degrees of support and career options tended to look pretty bleak. A lot has happened since then including the 2016 EPSRC RSE Fellows, the first international RSE conference and a host of University-RSE groups popping up all over the country.
In my talk, Is your Research Software Correct?, I tell the audience ‘If you need help, refer to your local RSE team. All good Universities have a central RSE team and if yours does not…..I refer you back to the word ‘good” Always leads to healthy debate when talking at an institution that’s yet to get involved :)
Centrally funded, University-wide RSE teams are useful because they offer a way to maintain a pool of expertise that can be costed into grants. It’s the model we are starting to employ at University of Sheffield following its success at trailblazing sites such as UCL and Manchester.
For this model to work, it is vital that we collaborate with researchers on getting RSE time costed into grants. In turn, researchers worry that they are asking funders for ‘something a bit strange’ which might lead to their project being turned down.
Asking for RSE Support in your grant is a Good Idea
There are two main arguments that I use when attempting to alleviate these concerns. The first is that we are quite successful in obtaining RSE funding, even in areas that you might not expect. The second is to point to funding calls where the funding council explicitly recommends RSE costing to be considered where appropriate.
The EPSRC have led the way in the UK with its RSE fellowship call, funding the Software Sustainability Institute (these days its funded by 3 research councils including BBSRC and ESRC) and various other initiatives.
Earlier this month, I was very happy to see that the BBSRC have explicitly mentioned Research Software Engineers in one of their latest calls: Machine Learning to Generate New Biological Understanding. In the call, the BBSRC say:
We note the significant contribution of staff such as Research Software Engineers (see external links) to interdisciplinary computational projects such as machine learning, and supports recognition of their contributions and encourages applicants to cost them appropriately on applications to this highlight.
I feel that this is a great move by the BBSRC and hope to see other funding councils follow their lead in future.
If you are a researcher and are currently writing scripts or developing code then I have a suggestion for you. If you haven’t done it already, get yourself a willing volunteer and send them your code/analysis/simulation/voodoo and ask them to run it on their machine to see what happens. Bonus points are awarded for choosing someone who uses a different operating system from you!
This simple act is one of the things I recommend in my talk Is Your Research Software Correct and it can often help improve both code and workflow.
It quickly exposes patterns that are not good practice. For example, scattered references to ‘/home/walkingrandomly/mydata.dat’ suddenly don’t seem like a great idea when your code buddy is running windows. The ‘minimal tweaking’ required to move your analysis from your machine to theirs starts to feel a lot less minimal as you get to the bottom of the second page of instructions.
Crashy McCrashFace
When I start working with someone new, the first thing I ask them to do is to provide access to their code and simple script called runme or similar that will build and run their code and spit out an answer that we agree is OK. Many projects stumble at this hurdle! Perhaps my compiler is different to theirs and objects to their abuse (or otherwise) of the standards or maybe they’ve forgotten to include vital dependencies or input data.
Email ping-pong ensues as we attempt to get the latest version…zip files with names like PhD_code_ver1b_ForMike_withdata_fixed.zip get thrown about while everyone wonders where Bob is because he totally got it working on Windows back in 2009.
git clone
‘Hey Mike, just clone the git repo and run the test suite. It should be fine because the latest continuous integration run didn’t throw up any issues. The benchmark code and data we’d like you to optimise is in the benchmarks folder along with the timings and results from our most recent tests. Ignore the papers folder, that just reproduces all of the results from our recent papers and links to Zenodo DOIs’
‘…………’
‘Are you OK Mike?’
‘I’m…..fine. Just have something in my eye’
I work at The University of Sheffield where I am one of the leaders of the new Research Software Engineering function. One of the things that my group does is help people make use of Sheffield’s High Performance Computing cluster, Iceberg.
Iceberg is a heterogenous system with around 3440 CPU cores and a sprinkling of GPUs. It’s been in use for several years and has been upgraded a few times over that period. It’s a very traditional HPC system that makes use of Linux and a variant of Sun Grid Engine as the scheduler and had served us well.

A while ago, the sysadmin pointed me to a goldmine of a resource — Iceberg’s accounting log. This 15 Gigabyte file contains information on every job submitted since July 2009. That’s more than 7 years of the HPC usage of 3249 users — over 46 million individual jobs.
The file format is very straightforward. There’s one line per job and each line consists of a set of colon separated fields. The first few fields look like something like this:
long.q:node54.iceberg.shef.ac.uk:el:abc07de:
The username is field 4 and the number of slots used by the job is field 35. On our system, slots correspond to CPU cores. If you want to run a 16 core job, you ask for 16 slots.
With one line of awk, we can determine the maximum number of slots ever requested by each user.
gawk -F: '$35>=slots[$4] {slots[$4]=$35};END{for(n in slots){print n, slots[n]}}' accounting > ./users_max_slots.csv
As a quick check, I grepped the output file for my username and saw that the maximum number of cores I’d ever requested was 20. I ran a 32 core MPI ‘Hello World’ job, reran the line of awk and confirmed that my new maximum was 32 cores.
There are several ways I could have filtered the number of users but I was having awk lessons from David Jones so let’s create a new file containing the users who have only ever requested 1 slot.
gawk -F: '$35>=slots[$4] {slots[$4]=$35};END{for(n in slots){if(slots[n]==1){print n, slots[n]}}}' accounting > users_where_max_is_one_slot.csv
Running wc on these files allows us to determine how many users are in each group
wc users_max_slots.csv 3250 6498 32706 users_max_slots.csv
One of those users turned out to be a blank line so 3249 usernames have been used on Iceberg over the last 7 years.
wc users_where_max_is_one_slot.csv 2393 4786 23837 users_where_max_is_one_slot.csv
That is, 2393 of our 3249 users (just over 73%) over the last 7 years have only ever run 1 slot, and therefore 1 core, jobs.
High Performance?
So 73% of all users have only ever submitted single core jobs. This does not necessarily mean that they have not been making use of parallelism. For example, they might have been running job arrays – hundreds or thousands of single core jobs performing parameter sweeps or monte carlo simulations.
Maybe they were running parallel codes but only asked the scheduler for one core. In the early days this would have led to oversubscribed nodes, possibly up to 16 jobs, each trying to run 16 cores.These days, our sysadmin does some voodoo to ensure that jobs can only use the number of cores that have been requested, no matter how many threads their code is spawning. Either way, making this mistake is not great for performance.
Whatever is going on, this figure of 73% is surprising to me!
Thanks to David Jones for the awk lessons although if I’ve made a mistake, it’s all my fault!
Update (11th Jan 2017)
UCL’s Ian Kirker took a look at the usage of their general purpose cluster and found that 71.8% of their users have only ever run 1 core jobs. https://twitter.com/ikirker/status/819133966292807680
I was in Stockholm last week to give an invited talk at the Workshop on Nordic Big Biomedical Data for Action. I was representing the Software Sustainability Institute and delivered the latest version of my talk Is Your Research Software Correct? 
It was a great event which introduced me to some nice initiatives going on waaaay up north. Initiatives such as Code Refinery who’s aims align well with those of the UK’s software sustainability Institute. Code refinery was introduced by Radovan Bast — Slide deck at http://cicero.xyz/v2/remark/github/coderefinery/talk-intro/niasc-2016/talk.md/#1

Other talks included the introduction of a scalable, parallel version of BLAST, Big Data Processing for Genomics and Delivering Bioinformatics Software as Virtual Machine images. I also got chance to geek out with some High Performance Computing and Bioinformatics people over interesting Swedish food.
Slides from most of the talks are available at http://www.nordicehealth.se/2016/12/04/workshop-on-nordic-big-biomedical-data-for-action/
I was recently invited to give a talk at the Sheffield R Users Group and decided to give a brief overview of how R relates to other technologies. Subjects included Mathematica’s integration of R, Intel’s compilers, Math Kernel Library and how they can make R faster and a range of Microsoft technologies including R Tools for Visual Studio, Microsoft R Open and the MRAN for reproducibility. I also touched upon the NAG Library, Maple’s code generation for R, GPUs and Spark.
- Slide deck: _ and R: How R relates to other technologies
Did I miss anything? If you were to give a similar talk, what might you have included?
“It gives me great pleasure to welcome you all to the first ever Research Software Engineering conference”
Rob Haines‘ opening line was met by thunderous applause from 202 people representing 14 different countries with a delegation that included funders, industry, academic researchers and, of course, research software engineers. The hairs on the back of my neck stood up as it dawned on me that this was a historic moment and that I was there when it happened. I wasn’t the only one

I felt like I’d come home and that these people were my tribe…and what a tribe!

Microsoft loves Linux
The conference was a mixture of talks, workshops and networking opportunities with the opening plenary given by Matthew Johnson of Microsoft Research. Microsoft was the gold sponsor for the event and the swag bag included one of these

I reflect on the fact that I’m currently using my Macbook Pro as a Windows 10 machine to access the linux subsystem — we’re not in Kansas anymore!
Microsoft is a keen supporter of the RSE movement although the job title they use is ‘Research Software Development Engineer’, a title they’ve used for several years now. An RSE (or RSDE) does much more software development than a typical researcher and more research than a typical software engineer.
The choice of job role is important since it defines how you are assessed for things such as promotion. This is an issue that some of us are working to address within academia because many RSEs are currently assessed using the same criteria as researchers.

Docker…we need more Docker
The conference included several practical workshops on all sorts of interesting topics but the most popular, by far, was the Docker workshop. It was so oversubscribed that access to the room had to be strictly controlled! Even I wasn’t allowed in and I was on the organising committee!
Fortunately, the materials are freely available on github – https://github.com/mfernandes61/RSE_Docker_course/wiki
Popularity of the @docker workshop at #RSE16 is off the chart! We need more docker workshops!
— Mike Croucher (@walkingrandomly) September 15, 2016
What a diff’rence a fellowship makes
I attended a discussion workshop called ‘The Role of the Research Software Engineer’ and gave a caffeine fueled lighting talk about the impact my EPSRC RSE fellowship has had within the University of Sheffield over its first six months. Slides are at https://mikecroucher.github.io/fellowship_difference/ but you might not get much from them since I like to talk over a set of images for things like this.
The EPSRC RSE Fellowship is the first of its kind and I believe that its had a huge impact on how the role of RSE is perceived by academic institutions. There were only 7 awards, however, so there is still so much more to be done.
Since members of the audience included representatives from various funding bodies, I wanted to help convince them that RSE fellowships are great value for money and they should consider launching their own.
Workshop materials
Here is a list of links to some of the workshop materials. If you know of one I’ve missed, please let me know.
- RSE Docker Course
- Data Visualisation (truthiness hurts)
- Introduction to concurrent programming with Go
Links
For more information about what happened on the day see the following links
- Simon Hetterick of the Software Sustainability Institute blogs about the conference at https://www.software.ac.uk/blog/2016-09-20-future-rses-looking-rosy-following-phenomenal-conference
- The twitter hashtag for the event was #RSE16 and this has been storified at https://storify.com/ResearchSoftEng/world-s-first-rse-conference
One of the great things about being a Research Software Engineer is the diversity of work you can get involved with. I specialise in smaller interventions which means that I can be working with physicists on Monday, engineers on Tuesday, geneticists on Wednesday….you get the idea.
Last month, I got to work with some Ecologists along with Anna Krystalli. We undertook the arduous journey from Sheffield down to Exeter to deliver talks and workshops at a post-conference symposium on reproducibility in science, organised by Malika Ihle and Isabel Winney, at the International Symposium on Behavioural Ecology.
I gave my talk, Is your research software correct?, and also delivered a workshop on using projects and version control using R and RStudio in the Code Cafe style. For the full write up of the day, see the excellent blog post by Anna over at the Mozilla Science Lab blog.
Updates : More resources
- Elevating the status of code in Ecology. Thanks to @katerererena for pointing this one out to me.
- Anna Krystalli’s course material