
MATLAB GPU / CUDA experiences on my laptop – Elementwise operations on the GPU #2
This is part 2 of an ongoing series of articles about MATLAB programming for GPUs using the Parallel Computing Toolbox. The introduction and index to the series is at https://www.walkingrandomly.com/?p=3730. All timings are performed on my laptop (hardware detailed at the end of this article) unless otherwise indicated.
Last time
In the previous article we saw that it is very easy to run MATLAB code on suitable GPUs using the parallel computing toolbox. We also saw that the GPU has its own area of memory that is completely separate from main memory. So, if you have a program that runs in main memory on the CPU and you want to accelerate part of it using the GPU then you’ll need to explicitly transfer data to the GPU and this takes time. If your GPU calculation is particularly simple then the transfer times can completely swamp your performance gains and you may as well not bother.
So, the moral of the story is either ‘Keep data transfers between GPU and host down to a minimum‘ or ‘If you are going to transfer a load of data to or from the GPU then make sure you’ve got a ton of work for the GPU to do.‘ Today, I’m going to consider the latter case.
A more complicated elementwise function – CPU version
Last time we looked at a very simple elementwise calculation– taking the sine of a large array of numbers. This time we are going to increase the complexity ever so slightly. Consider trig_series.m which is defined as follows
function out = myseries(t) out = 2*sin(t)-sin(2*t)+2/3*sin(3*t)-1/2*sin(4*t)+2/5*sin(5*t)-1/3*sin(6*t)+2/7*sin(7*t); end
Let’s generate 75 million random numbers and see how long it takes to apply this function to all of them.
cpu_x = rand(1,75*1e6)*10*pi; tic;myseries(cpu_x);toc
I did the above calculation 20 times using a for loop and took the median of the results to get 4.89 seconds1. Note that this calculation is fully parallelised…all 4 cores of my i7 CPU were working on the problem simultaneously (Many built in MATLAB functions are parallelised these days by the way…No extra toolbox necessary).
GPU version 1 (Or ‘How not to do it’)
One way of performing this calculation on the GPU would be to proceed as follows
cpu_x =rand(1,75*1e6)*10*pi; tic %Transfer data to GPU gpu_x = gpuArray(cpu_x); %Do calculation using GPU gpu_y = myseries(gpu_x); %Transfer results back to main memory cpu_y = gather(gpu_y) toc
The mean time of the above calculation on my laptop’s GPU is 3.27 seconds, faster than the CPU version but not by much. If you don’t include data transfer times in the calculation then you end up with 2.74 seconds which isn’t even a factor of 2 speed-up compared to the CPU.
GPU version 2 (arrayfun to the rescue)
We can get better performance out of the GPU simply by changing the line that does the calculation from
gpu_y = myseries(gpu_x);
to a version that uses MATLAB’s arrayfun command.
gpu_y = arrayfun(@myseries,gpu_x);
So, the full version of the code is now
cpu_x =rand(1,75*1e6)*10*pi; tic %Transfer data to GPU gpu_x = gpuArray(cpu_x); %Do calculation using GPU via arrayfun gpu_y = arrayfun(@myseries,gpu_x); %Transfer results back to main memory cpu_y = gather(gpu_y) toc
This improves the timings quite a bit. If we don’t include data transfer times then the arrayfun version completes in 1.42 seconds down from 2.74 seconds for the original GPU code. Including data transfer, the arrayfun version complete in 1.94 seconds compared to for the 3.27 seconds for the original.
Using arrayfun for the GPU is definitely the way to go! Giving the GPU every disadvantage I can think of (double precision, including transfer times, comparing against multi-thread CPU code etc) we still get a speed-up of just over 2.5 times on my laptop’s hardware. Pretty useful for hardware that was designed for energy-efficient gaming!
Note: Something that I learned while writing this post is that the first call to arrayfun will be slower than all of the rest. This is because arrayfun compiles the MATLAB function you pass it down to PTX and this can take a while (seconds). Subsequent calls will be much faster since arrayfun will use the compiled results. The compiled PTX functions are not saved between MATLAB sessions.
arrayfun – Good for your memory too!
Using the arrayfun function is not only good for performance, it’s also good for memory management. Imagine if I had 100 million elements to operate on instead of only 75 million. On my 3Gb GPU, the following code fails:
cpu_x = rand(1,100*1e6)*10*pi;
gpu_x = gpuArray(cpu_x);
gpu_y = myseries(gpu_x);
??? Error using ==> GPUArray.mtimes at 27
Out of memory on device. You requested: 762.94Mb, device has 724.21Mb free.
Error in ==> myseries at 3
out =
2*sin(t)-sin(2*t)+2/3*sin(3*t)-1/2*sin(4*t)+2/5*sin(5*t)-1/3*sin(6*t)+2/7*sin(7*t);
If we use arrayfun, however, then we are in clover. The following executes without complaint.
cpu_x = rand(1,100*1e6)*10*pi; gpu_x = gpuArray(cpu_x); gpu_y = arrayfun(@myseries,gpu_x);
Some Graphs
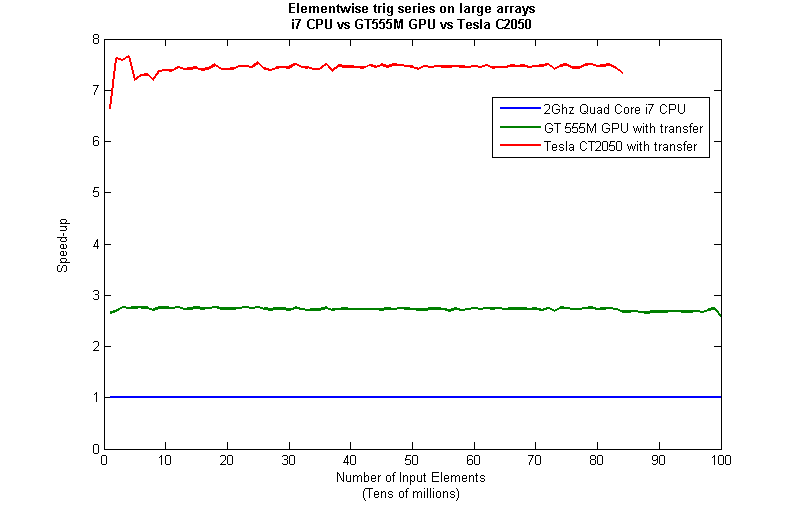
Just like last time, I ran this calculation on a range of input arrays from 1 million to 100 million elements on both my laptop’s GT 555M GPU and a Tesla C2050 I have access to. Unfortunately, the C2050 is running MATLAB 2010b rather than 2011a so it’s not as fair a test as I’d like. I could only get up to 84 million elements on the Tesla before it exited due to memory issues. I’m not sure if this is down to the hardware itself or the fact that it was running an older version of MATLAB.

Next, I looked at the actual speed-up shown by the GPUs compared to my laptop’s i7 CPU. Again, this includes data transfer times, is in full double precision and the CPU version was multi-threaded (No dodgy ‘GPUs are awesome’ techniques used here). No matter what array size is used I get almost a factor of 3 speed-up using the laptop GPU and more than a factor of 7 speed-up when using the Tesla. Not too shabby considering that the programming effort to achieve this speed-up was minimal.
Conclusions
- It is VERY easy to modify simple, element-wise functions to take advantage of the GPU in MATLAB using the Parallel Computing Toolbox.
- arrayfun is the most efficient way of dealing with such functions.
- My laptop’s GPU demonstrated almost a 3 times speed-up compared to its CPU.
Hardware / Software used for the majority of this article
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit. I’m not using Linux because of the lack of official support for Optimus.
- MATLAB: 2011a with the parallel computing toolbox
Code and sample timings (Will grow over time)
You need myseries.m and trigseries_test.m and the Parallel Computing Toolbox. These are the times given by the following function call for various systems (transfer included and using arrayfun).
[cpu,~,~,~,gpu] = trigseries_test(10,50*1e6,'mean')
GPUs
- Tesla C2050, Linux, 2010b – 0.4751 seconds
- NVIDIA GT 555M – 144 CUDA Cores, 3Gb RAM, Windows 7, 2011a – 1.2986 seconds
CPUs
- Intel Core i7-2630QM, Windows 7, 2011a (My laptop’s CPU) – 3.33 seconds
- Intel Core 2 Quad Q9650 @ 3.00GHz, Linux, 2011a – 3.9452 seconds
Footnotes
1 – This is the method used in all subsequent timings and is similar to that used by the File Exchange function, timeit (timeit takes a median, I took a mean). If you prefer to use timeit then the function call would be timeit(@()myseries(cpu_x)). I stick to tic and toc in the article because it makes it clear exactly where timing starts and stops using syntax well known to most MATLABers.
Thanks to various people at The Mathworks for some useful discussions, advice and tutorials while creating this series of articles.
I would suggest you consider Jacket when performing these benchmarks too.
I made two changes
1) gpuArray with gdouble to transfer to gpu
2) gather with double to transfer back to cpu
Here are the results:
(All using Linux, 2010b)
CPUS
Intel Core i7-920, @ 2.67Ghz: 2.9640
Intel Core 2 Quad Q9400 @ 2.66Ghz: 4.5684
GPUs using PCT
Tesla C2090: 0.4959
Quadro 6000: 0.6692
GPUs using Jacket
Tesla C2090: 0.4406
Quadro 6000: 0.5881
As you can see even for the same basic elementary operations, jacket is slightly faster on the Tesla, but much faster on the Quadro. This is mostly because Jacket uses just in time compilation to batch all the operations together. And if you get into using actual heavy weight functions, here is a comparision http://www.accelereyes.com/products/compare
I hope you give Jacket an honest try.
Hi Pavan
Thanks for the figures. Jacket looks like a great product and the only reason I am not considering it in this series is cost. WalkingRandomly is a personal website that is fully funded by me and I simply cannot afford the multiple Jacket licenses that I’d need (Note the distinct lack of advertising on the site…this place hardly earns me a thing).
My University has hundreds of network licenses for the PCT, bought primarily to improve utilisation of multi-core machines. So, I can try out benchmarks such as these on as many different types of hardware as I can get my hands on at no extra cost.
Best Wishes,
Mike
I am planning to buy a new laptop and I use Matlab every day. It would be great if you can throw light on performances of i5- dual core and i7 2670QM processor w.r.t to Matlab, preferably quantify in terms of numbers as u did in this post, if its possible :)
Thanks
If someone would like to provide me with the hardware then I would galdly oblige :)