Over the years I’ve been blogging, I have run a few recurring series of blogposts. In the early days, there was the shortlived Problem of The Week. Sometime later I inherited The Carnival of Maths which I looked after for a couple of years before passing it over to Aperiodical.com who have looked after it ever since. I also ran a series called A Month of Math Software for 2 and a half years before my enthusiasm for the topic ran out.
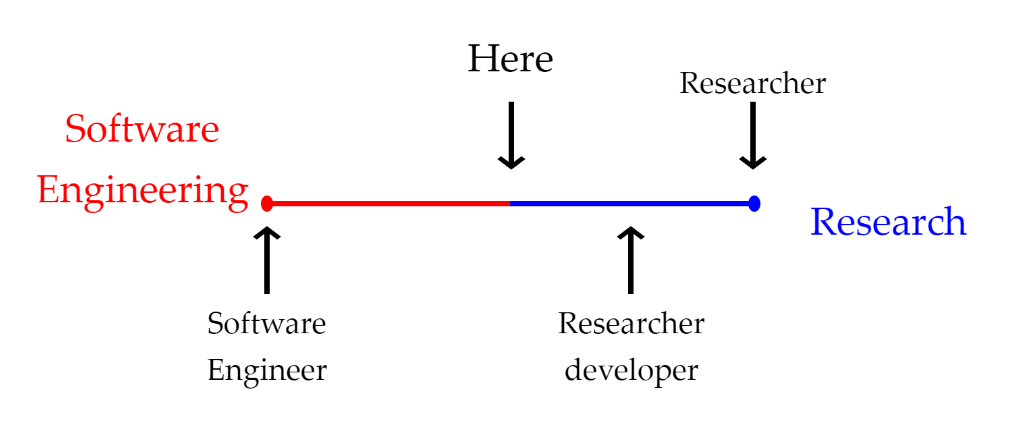
I am currently the Head of Research Computing at The University of Leeds — a senior management role that puts me in the fortunate position of being reasonably well-informed about the world of research computing. Software, hardware, cloud, data science, dealing with sensitive data…everyone, it seems, has something to tell me. I’m also continuing with my EPSRC fellowship part-time which means that I’m rather more hands on than a typical member of an executive leadership team.
While at JuliaCon 2018, I had the extremely flattering experience of a few people telling me that they had been long time readers of WalkingRandomly and that they were disappointed that I didn’t post as often
All of this has led to the desire to start a new regular series. One where I look at all aspects of research computing and compile it into a series of monthly posts. If you have anything you’d like including in next months’ post — contact me via the usual channels.
Botched code causes seven-year scientific argument
For the last couple of years, I have given a talk around the UK and Europe called ‘Is your Research Software Correct‘ (unlike this other talk of mine, it has not yet been recorded but I’ll soon remedy that! Let me know if you can offer a venue with good recording facilities).
I start off by asking the audience to Imagine….imagine that the results of your latest simulation or data analysis are in and they are amazing. Your heart beats faster, this result changes everything and you know it. This is why you entered science, this is what you always hoped for. Papers in journals like Nature or Science — no problem. Huge grant to follow up this work…professorship….maybe, you dare to dream, this could lead to a nobel prize. Only one minor problem — the code is completely wrong and you just haven’t figured it out yet.
In the talk (based originally on an old blog post here) I go on to suggest and discuss some simple practices that might help the situation. Scripting and coding instead of pointy-clicky solutions, version control, testing, open source your software, software citation etc. None of it is mind blowing but I firmly believe that if all of the advice was taken, we’d have fewer situations like this one…..
Long story short, Two groups were investigating what happens when you super-freeze water. They disagreed and much shouting happened for 7 years. There was a bug in the code of one group. A great article discussing the saga is available over at Physics Today:
https://physicstoday.scitation.org/do/10.1063/PT.6.1.20180822a/full/
Standout quotes that may well end up in a future version of Is Your Research Software Correct include
“One of the real travesties,” he says, is that “there’s no way you could have reproduced [the Berkeley team’s] algorithm—the way they had implemented their code—from reading their paper.” Presumably, he adds, “if this had been disclosed, this saga might not have gone on for seven years”
and
Limmer maintains that he and his mentor weren’t trying to hide anything. “I had and was very willing to share the code,” he says. What he didn’t have, he says, was the time or personnel to prepare the code in a form that could be useful to an outsider. “When Debenedetti’s group was making their code available,” Limmer explains, “he brought people in to clean up the code and document and run tests on it. He had resources available to him to be able to do that.” At Berkeley, “it was just me trying to get that done myself.”
Which is a case study for asking for Research Software Engineer support in a grant if ever I saw one.
Julia gets all grown up — version 1.0 released at JuliaCon 2018
One of the highlights of the JuliaCon 2018 conference was the release of Julia version 1.0 — a milestone that signifies that the new-language-on-the block has reached a certain level of maturity. We celebrated the release at University of Leeds by installing it on our most recent HPC system – ARC3.
In case you don’t know, Julia is a relatively new free and open source language for technical computing. It works on everything from Raspberry Pi up to HPC systems with thousands of Cores. It’s the reason for the letters Ju in Project Jupyter and aims to be an easy to use language (along the lines of Python, R or MATLAB) with the performance of languages like Fortran or C.
UK Research Software Engineering Association Webinar series
The UK Research Software Engineering Association is starting a new webinar series this month with a series of planned topics including an Introduction to Object-Oriented Design for Scientists, Interfacing to/from Python with C, FORTRAN or C++ and Meltdown for Dummies.
These webinars are free to join, and you do not need to register in advance. Full details including the link to join the webinar are available below.
For more information on the RSE webinar series, including information on how to propose a webinar and information on upcoming webinars, please see:
https://rse.ac.uk/events/rse-webinar-series
This page will also have links to recordings of past webinars when they become available.
Verification and Modernisation of Fortran Codes using the NAG Fortran Compiler
There is still a huge amount of research software written in Fortran. Indeed, software written in Fortran are, by far, the most popular codes run on the UK’s national supercomputer service, Archer (See http://www.archer.ac.uk/status/codes/ for up to date stats).
Fortran compilers are not created equally and many professional Fortran developers will suggest that you develop against more than one. Gfortran is probably essential if you want your code to be usable by all but the Intel Fortran Compiler can often produce the fastest executables on x86 hardware and the NAG Compiler is useful for ensuring correctness.
This webinar by NAG’s Wadud Miah promises to show what the NAG Fortran Compiler can do for your Fortran code.
New Macbook Pro has 6 CPU cores but….
Apple’s new Macbook Pro laptops have a fantastic looking CPUs in them with the top of the line boasting 6 cores and turbo boost up to 4.8Ghz. Sounds amazing for simulation work but it seems that there are some thermal issues that prevent it from running at top speed for long.
Contact me to get your news included next month
That’s all I have for this first article in the series. If you have any research computing news that you’d like included in the next edition, contact me.