UK to launch 6 major HPC centres
Tomorrow, I’ll be attending the launch event for the UK’s new HPC centres and have been asked to deliver a short talk as part of the program. As someone who paddles in the shallow-end of the HPC pool I find this both flattering and more than a little terrifying. What can little-ole-me say to the national HPC glitterati that might be useful?
This blog post is an attempt at gathering my thoughts together for that talk.
The technology gap in research computing
Broadly speaking, my role in academia is to hang out with researchers, compute providers (cloud and HPC) and software vendors in an attempt to be vaguely useful in the area of research software. I’m a Research Software Engineer with a focus on Long Tail Science: The large number of very small research groups who do a huge amount of modern research.
Time and again, what I see can be summarized in this quote by Greg Wilson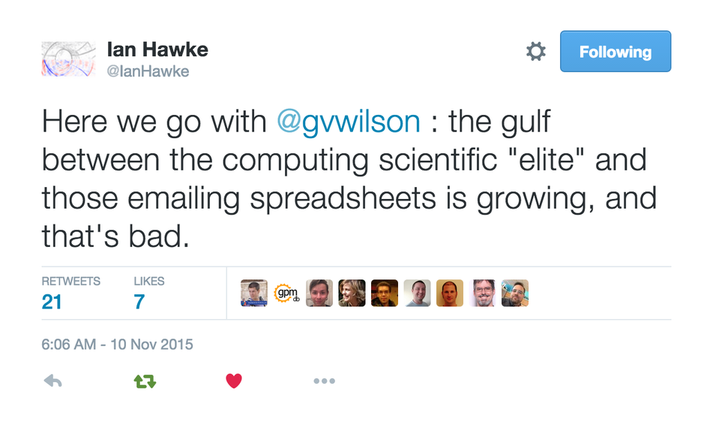
This is very true in the world of High Performance Computing.
Geek Top Gear
I love technology and I love HPC in particular. I love to geek out on Flops, Ghz, SIMD instructions, GPUs, FPGAs…..all that stuff. I help support The University of Sheffield’s local HPC service and worked in Research IT at The University of Manchester for around a decade before moving to Sheffield.
I’ve given and seen many a HPC-related talk in my time and have certainly been guilty of delivering what I now refer to as the ‘Geek Top Gear’ speech. For maximum effect, you need to do it in a Jeremy Clarkson voice and, if you’re feeling really macho, kiss your bicep at the point where you tell the audience how many Petaflops your system can do in Linpack.
*Begin Jeremy Clarkson Impression*
Our new HPC system has got 100,000 of the latest Intel Kaby Lake cores...which is a lot!
Usually running at 2.6Ghz, these cores can turbo-boost to 3.2Ghz for those moments when we need that extra boost of power. Obviously, being Kaby Lake, these cores have all the instruction extensions you’d expect with AVX2, FMA, SSE, ABM and many many other TLAs for all your SIMD needs. Of course every HPC system needs accelerators…..and we have the best of them: Xeon Phis with 68 cores each and NVIDIA GPUs with thousands of tiny little cores will handle every massively parallel job you can throw at them….Easily. We connect these many many cores together with high-speed interconnect fashioned from threads of pure unicorn hair and cool the whole thing with the tears of virigin nerds.
YEEEEEES! Our new HPC system is the best one since the last one and, achieving over a Gajillion Petaflops in the Linpack test (kiss bicep), it will change your life forever.

Any questions?
Audience member 1: What’s a core?
Audience member 2: Why does it run my R script slower than my laptop?
Audience member 3: Do you have Excel installed on it?
There is a huge gap between what many HPC providers like to focus on and what the typical long-tail researcher wants or needs. I propose that the best bridge for this gap is the Research Software Engineer (RSE).
Research Software Engineer as Alpine guide
In my fellowship proposal, I compared the role of a Research Software Engineer to that of an alpine guide:
Technological development in software is more like a cliff-face than a ladder – there are many routes to the top, to a solution. Further, the cliff face is dynamic – constantly and quickly changing as new technologies emerge and decline. Determining which technologies to deploy and how best to deploy them is in itself a specialist domain, with many features of traditional research.
Researchers need empowerment and training to give them confidence with the available equipment and the challenges they face. This role, akin to that of an Alpine guide, involves support, guidance, and load carrying. When optimally performed it results in a researcher who knows what challenges they can attack alone, and where they need appropriate support. Guides can help decide whether to exploit well-trodden paths or explore new possibilities as they navigate through this dynamic environment.
At Sheffield, we have built a pool of these Research Software Engineers to provide exactly this kind of support and it’s working extremely well so far. Not only are we helping individual research groups but we are also using our experiences in the field to help shape the University HPC environment in collaboration with the IT department.
Supercomputing: Irrelevant to many?
“Never bring an anecdote to a data-fight” so the saying goes and all I have from my own experiences are a bucket load of anecdotes, case studies and cursory log-mining experiments that indicate that even those who DO use HPC are not doing so effectively. Fortunately, others have stepped up to the plate and we have survey and interview data on how researchers are using compute resources.
How Do Scientists Develop and Use Scientific Software? is a report on a 2009 survey of 1972 researchers from around the world. They found that “79.9% of the scientists never use scientific software on a supercomputer”
When I first learned of this number, I found it faintly depressing. This technology that I love so much and for which University IT departments dedicate special days to seems to be pretty much irrelevant to the majority of researchers. Could it be that even in an era of big data, machine learning and research software engineering that most people only need a laptop?
Only ever needing a laptop certainly doesn’t fit with what I’ve seen while working in the trenches. Almost every researcher I’ve met who does computational research wishes it was faster or that they had more memory to allow them to do larger problems. Speed is the easiest thing to sell to researchers in the world of RSE. They come for faster execution and leave with a side-order of version control, testing and documentation. A combination of software development and migration to even a small HPC system can easily result in 100x or even 1000x speed-ups for many researchers.
In my experience, it’s not that researchers don’t need HPC, it’s that the jump from their laptop-based workflow to one that makes good use of a HPC system is too large for them to bridge without a little help. Providing that help can result in some great partnerships such as the recent one between the Sheffield RSE group and the Sheffield Faculty of Arts and Humanities.

Want to know how that partnership started? I compiled an experimental R/Rcpp package that they were struggling with and then took them for coffee and said ‘That code took a while to run. Here’s how we can make it go faster….Now…what exactly are you doing because it looks cool?’ Fast forward a year or so and we are on the cusp of starting a great new project that will include traditional HPC and cloud computing as part of their R-based workflow.
My experiences seem to be reflected in the data. In their 2011 article, A Survey of the Practice of Computational Science, Prabhu et al interviewed 114 randomly selected researchers from Princeton University. Princeton have a very strong, well supported HPC centre which provides both resources and the expertise to use them. Even at such a well equipped institution, the authors write that ‘Despite enormous wait times, many scientists run their programs only on desktops’ although they did report much higher HPC usage compared to the Hanny et al survey.
Other salient quotes from the Prabhu interviews include
“only 18% of researchers who optimize code leveraged profiling tools to inform their optimization plans”
“only 7% of researchers leveraged any form of thread based shared memory CPU parallelism”
“Only 11% of researchers utilized loop based parallelism”
“Currently, many researchers fit their scientific models to only a subset of available parameters for faster program runs.”
“Across disciplines, an order of magnitude performance improvement was cited as a requirement for significant changes in research quality”
HPC: There’s plenty of room at the bottom
Potential users of HPC look different to those of 20 years ago. The popularity explosion of languages such as MATLAB, Python and R have democratized programming and the world is awash with inefficient research software. Most of the time, this lack of efficiency is not a problem (see ‘In defense of inefficient scientific code‘) but if a researcher needs to scale up what they are doing, it can become limiting. Researchers might wait for days for the results to come in and limit the scope of their investigations to fit the hardware they have access to — their laptop usually.
The paper of Prabu et al said that an order of magnitude (10x) speed up was cited by researchers as a requirement for significant changes in research quality. For an experienced Research Software Engineer with access to cloud or HPC facilities, a 10x speed-up is usually pretty easy to achieve for this new audience. 100x or even 1000x can be achieved fairly frequently if you employ multiple hardware and software techniques. Compared to squeezing out a few percent more performance from HPC-centric code such as LAPACK or CASTEP, it’s not even all that difficult. I recently sped up one researcher’s MATLAB code by a factor of 800x in a couple of days and I’m a fairly middling developer if I’m brutally honest.
The whole point of High Performance Computing is to accelerate science and right now there is more computational science around than there has ever been before. Furthermore, it’s easier than ever to accelerate! There’s plenty of room at the bottom.
Closing the computational gap with people, training and compute power
The UK’s 6 new HPC centers represent the cutting edge of hardware technology. They provide a crucial component of our national hardware infrastructure, will contribute to research in HPC itself and will doubtless be of huge benefit to computational science. Furthermore, all of the funded proposals include significant engagement with the national Research Software Engineering community – the vital bridge between many researchers and HPC.
Co-development of research software with effort from both RSEs and researchers can be an extremely powerful model. Combine this with further collaboration between RSEs and compute providers and we have an environment that I think is both very exciting and capable of helping to close the rich/poor compute divide.
As an RSE who works with both researchers and University-level HPC providers, I ask for 3 things to be considered by these new regional centres.
- Enjoy your new compute-ferraris. I look forward to seeing how hard you can push them.
- You will be learning new good practice in how to provide HPC services. Disseminate this to those of us running smaller services.
- There’s plenty of room at the bottom! Help us to support the new wave of computational researchers.
Thanks to languages such as MATLAB, Python and R, general purpose programming has been fully democratized. I look forward to working with these new centres to help democratize high performance computing.