
Search Results
While waiting for the rain to stop before heading home, I started messing around with the heart equation described in an old WalkingRandomly post. Playing code golf with myself, I worked to get the code tweetable. In Python:
from pylab import *
x=r_[-2:2:0.001]
show(plot((sqrt(cos(x))*cos(200*x)+sqrt(abs(x))-0.7)*(4-x*x)**0.01)) pic.twitter.com/gbOTbYSaIG— Mike Croucher (@walkingrandomly) February 8, 2016
In R:
x=seq(-2,2,0.001)
y=Re((sqrt(cos(x))*cos(200*x)+sqrt(abs(x))-0.7)*(4-x*x)^0.01)
plot(x,y)#rstats pic.twitter.com/trpgEnNna4— Mike Croucher (@walkingrandomly) February 8, 2016
I liked the look of the default plot in R so animated it by turning 200 into a parameter that ranged from 1 to 200. The result was this animation:
Finding this animation based on previous tweets oddly mesmerising #rstats pic.twitter.com/e3q6lZqWcP
— Mike Croucher (@walkingrandomly) February 8, 2016
The code for the above isn’t quite tweetable:
options(warn=-1)
for(num in seq(1,200,1))
{
filename = paste("rplot" ,sprintf("%03d", num),'.jpg',sep='')
jpeg(filename)
x=seq(-2,2,0.001)
y=Re((sqrt(cos(x))*cos(num*x)+sqrt(abs(x))-0.7)*(4-x*x)^0.01)
plot(x,y,axes=FALSE,ann=FALSE)
dev.off()
}
This produces a lot of .jpg files which I turned into the animated gif with ImageMagick:
convert -delay 12 -layers OptimizeTransparency -colors 8 -loop 0 *.jpg animated.gif
I’ve seen several equations that plot a heart shape over the years but a recent google+ post by Lionel Favre introduced me to a new one. I liked it so much that I didn’t want to wait until Valentine’s day to share it. In Mathematica:
Plot[Sqrt[Cos[x]]*Cos[200*x] + Sqrt[Abs[x]] - 0.7*(4 - x*x)^0.01, {x, -2, 2}]
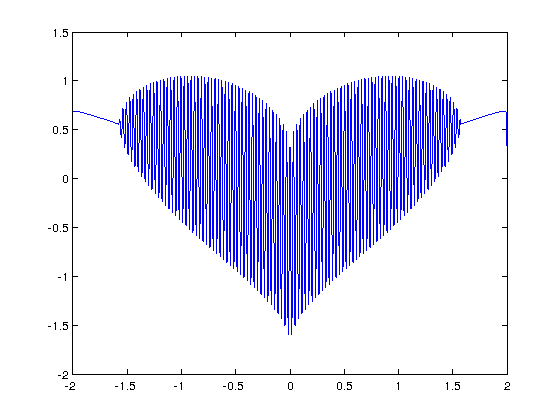
and in MATLAB:
>> x=[-2:.001:2]; >> y=(sqrt(cos(x)).*cos(200*x)+sqrt(abs(x))-0.7).*(4-x.*x).^0.01; >> plot(x,y) Warning: Imaginary parts of complex X and/or Y arguments ignored
The result from the MATLAB version is shown below
Update
Rene Grothmann has looked at this equation in a little more depth and plotted it using Euler.
Similar posts
I imagine that most of the people reading this will know what the Tangram puzzle is but just in case you are not one of them here is a quick excerpt from the Wikipedia page which says it all:
“Tangram (Chinese: 七巧板; pinyin: qī qiǎo bǎn; literally “seven boards of skill”) is a dissection puzzle. It consists of seven pieces, called tans, which fit together to form a shape of some sort. The objective is to form a specific shape with seven pieces. The shape has to contain all the pieces, which may not overlap. ”
The classical Tangram puzzle looks like this:

It is possible to make many shapes from these pieces; some of which are below (taken from tangrams.ca)

If you would like to have a go at making your own Tangram shapes then you can make your own Tangram set out of paper, buy a nice wooden one, try this java applet or use this Mathematica demonstration (written by ) using the free Mathplayer from Wolfram Research. There is even a Tangram game for the Nintendo DS
!
In the week leading up to Valentine’s day I wondered if there is a standard variation of the classical Tangram puzzle that is constructed from a heart shape and I was delighted to discover that there is. Using Enrique’s Mathematica code as a starting point I wrote a demonstration called Broken Heart Tangram and it was published on the Wolfram Demonstrations site today.

I hope you have fun with this demonstration and would love to see some of the shapes that you come up with. As always, comments are welcomed.
Other articles you may like
For my final Valentine’s day post I thought I would share a minor discovery I made while playing around with the polar equation

When n=1 the graph of this equation is a rotated cardioid which is exactly what I expected after reading the Math World page on the Heart Curve.

While playing around with the parameters I discovered that if you increase the value of n (to 10 say) then the resulting plot looks like a flower.
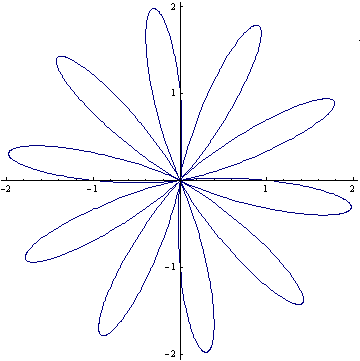
Very apt considering the time of year I think. If you would like to play with this equation yourself then feel free to try my very simple Wolfram Demonstration which was published today.
Over the years I’ve been blogging, I have run a few recurring series of blogposts. In the early days, there was the shortlived Problem of The Week. Sometime later I inherited The Carnival of Maths which I looked after for a couple of years before passing it over to Aperiodical.com who have looked after it ever since. I also ran a series called A Month of Math Software for 2 and a half years before my enthusiasm for the topic ran out.
I am currently the Head of Research Computing at The University of Leeds — a senior management role that puts me in the fortunate position of being reasonably well-informed about the world of research computing. Software, hardware, cloud, data science, dealing with sensitive data…everyone, it seems, has something to tell me. I’m also continuing with my EPSRC fellowship part-time which means that I’m rather more hands on than a typical member of an executive leadership team.
While at JuliaCon 2018, I had the extremely flattering experience of a few people telling me that they had been long time readers of WalkingRandomly and that they were disappointed that I didn’t post as often
All of this has led to the desire to start a new regular series. One where I look at all aspects of research computing and compile it into a series of monthly posts. If you have anything you’d like including in next months’ post — contact me via the usual channels.
Botched code causes seven-year scientific argument
For the last couple of years, I have given a talk around the UK and Europe called ‘Is your Research Software Correct‘ (unlike this other talk of mine, it has not yet been recorded but I’ll soon remedy that! Let me know if you can offer a venue with good recording facilities).
I start off by asking the audience to Imagine….imagine that the results of your latest simulation or data analysis are in and they are amazing. Your heart beats faster, this result changes everything and you know it. This is why you entered science, this is what you always hoped for. Papers in journals like Nature or Science — no problem. Huge grant to follow up this work…professorship….maybe, you dare to dream, this could lead to a nobel prize. Only one minor problem — the code is completely wrong and you just haven’t figured it out yet.
In the talk (based originally on an old blog post here) I go on to suggest and discuss some simple practices that might help the situation. Scripting and coding instead of pointy-clicky solutions, version control, testing, open source your software, software citation etc. None of it is mind blowing but I firmly believe that if all of the advice was taken, we’d have fewer situations like this one…..
Long story short, Two groups were investigating what happens when you super-freeze water. They disagreed and much shouting happened for 7 years. There was a bug in the code of one group. A great article discussing the saga is available over at Physics Today:
https://physicstoday.scitation.org/do/10.1063/PT.6.1.20180822a/full/
Standout quotes that may well end up in a future version of Is Your Research Software Correct include
“One of the real travesties,” he says, is that “there’s no way you could have reproduced [the Berkeley team’s] algorithm—the way they had implemented their code—from reading their paper.” Presumably, he adds, “if this had been disclosed, this saga might not have gone on for seven years”
and
Limmer maintains that he and his mentor weren’t trying to hide anything. “I had and was very willing to share the code,” he says. What he didn’t have, he says, was the time or personnel to prepare the code in a form that could be useful to an outsider. “When Debenedetti’s group was making their code available,” Limmer explains, “he brought people in to clean up the code and document and run tests on it. He had resources available to him to be able to do that.” At Berkeley, “it was just me trying to get that done myself.”
Which is a case study for asking for Research Software Engineer support in a grant if ever I saw one.
Julia gets all grown up — version 1.0 released at JuliaCon 2018
One of the highlights of the JuliaCon 2018 conference was the release of Julia version 1.0 — a milestone that signifies that the new-language-on-the block has reached a certain level of maturity. We celebrated the release at University of Leeds by installing it on our most recent HPC system – ARC3.
In case you don’t know, Julia is a relatively new free and open source language for technical computing. It works on everything from Raspberry Pi up to HPC systems with thousands of Cores. It’s the reason for the letters Ju in Project Jupyter and aims to be an easy to use language (along the lines of Python, R or MATLAB) with the performance of languages like Fortran or C.
UK Research Software Engineering Association Webinar series
The UK Research Software Engineering Association is starting a new webinar series this month with a series of planned topics including an Introduction to Object-Oriented Design for Scientists, Interfacing to/from Python with C, FORTRAN or C++ and Meltdown for Dummies.
These webinars are free to join, and you do not need to register in advance. Full details including the link to join the webinar are available below.
For more information on the RSE webinar series, including information on how to propose a webinar and information on upcoming webinars, please see:
https://rse.ac.uk/events/rse-webinar-series
This page will also have links to recordings of past webinars when they become available.
Verification and Modernisation of Fortran Codes using the NAG Fortran Compiler
There is still a huge amount of research software written in Fortran. Indeed, software written in Fortran are, by far, the most popular codes run on the UK’s national supercomputer service, Archer (See http://www.archer.ac.uk/status/codes/ for up to date stats).
Fortran compilers are not created equally and many professional Fortran developers will suggest that you develop against more than one. Gfortran is probably essential if you want your code to be usable by all but the Intel Fortran Compiler can often produce the fastest executables on x86 hardware and the NAG Compiler is useful for ensuring correctness.
This webinar by NAG’s Wadud Miah promises to show what the NAG Fortran Compiler can do for your Fortran code.
New Macbook Pro has 6 CPU cores but….
Apple’s new Macbook Pro laptops have a fantastic looking CPUs in them with the top of the line boasting 6 cores and turbo boost up to 4.8Ghz. Sounds amazing for simulation work but it seems that there are some thermal issues that prevent it from running at top speed for long.
Contact me to get your news included next month
That’s all I have for this first article in the series. If you have any research computing news that you’d like included in the next edition, contact me.
In this article, I find myself in the rather odd position of interviewing myself as part of my series of interviews with the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I completed a PhD in theoretical physics in 2005 at The University of Sheffield where my area of research was photonic crystals. The most important thing I learned during my PhD is that I was a lot better at solving computational problems than I was at Physics. In particular, I seemed to be a lot better at solving other people’s problems rather than inventing and solving my own.
This led me to consider a job at The University of Manchester in the centralised Applications Support Team with IT Services. This team looked fantastic! Its role was to support Manchester’s extensive site licensed application portfolio – MATLAB, Mathematica, Intel Compilers, SPSS, Abaqus…that sort of thing. It included aspects of licensing, sysadmin, installation support, high performance computing, consultancy, teaching – you name it! Sadly, 6 months after I started at Manchester, there was the first of many IT department restructures and the team was disbanded.
The centralised service was devolved into the faculties (It’s centralised again now!) and I ended up in the faculty of Engineering and Physical Sciences. I took the responsibility of supporting a portfolio of applications with me. Broadly speaking, I became ‘the MATLAB guy’ at Manchester but also started extending support into the open source world — Python, R, Octave and so on. This was done organically: I went were the work took me. If lots of academics came with problems in foo, I learned about foo, solved problems in foo and started teaching how to do foo better. If ‘foo’ happened to be distasteful to me — such as VBA — well, tough! To be successful in support, you must do the job that’s put in front of you. It’s a little like an Accident and Emergency department.
Very early on, I learned that the path to a researcher’s heart was speed. They wanted results and they wanted them fast! There was a team at Manchester doing hardcore Fortran/MPI stuff and they had that market sewn up — there was no space for the likes of me there. So, I took advantage of being ‘The MATLAB guy’ and started offering programming services to whoever wanted them for free. I could often achieve 100x speed-ups with less than a day’s work and this made me pretty popular!
I got to see a lot of code and that’s where the problems started. I’d get code with names like phdresults_dec2006_ver12_broken_fixed_FORMIKE.m that wouldn’t run on my machine. I’d learn that my machine was the second machine it had ever been run on and I was the second person to ever see the code. There would be 1000s of lines of code with no version control and no tests which made refactoring scary!
I learned that a huge amount of computational research was being done inefficiently. I feel that I need to be very clear: when I say ‘inefficient’, I’m not referring to Fortran code, say, that’s not making optimal use of the cache, SIMD instructions or has poor scaling over 128 cores. When I was young, this is where I thought the work would be. Sure, there’s some, but that’s not where you can help the most people.
A much more common situation, I find, is a researcher who’s workflow includes a huge amount of manual work. PhD students (and in one notable case, a very senior professor!) who manually edit 100s of spreadsheets for example. A morning’s work spent on some simple automation can completely change their lives!
These experiences got me interested in how to improve the general level of software engineering practice in research. I became a Software Sustainability Institute fellow in 2013, discovered this huge, amazing community and the rest is history.
You recently left Manchester University to move to Sheffield? What was behind that?
Prof. Neil Lawrence met me in The Sheffield Tap one evening and said ‘How would you like to ditch your commute and change the world?’ He was interested in bringing some of the research software initiatives I’d worked on in Manchester over to Sheffield as part of his Open Data Science initiative.
Changing the world sounded interesting but he had me at ‘ditch the commute’ if I’m being honest. I’ve lived in Sheffield for 20 years and commuted to Manchester by train for 10 of those. On some days, my twitter feed @walkingrandomly degenerated into little more than rants against various train companies! I needed to stop.
Working with Neil and the University of Sheffield has been an amazing experience. There’s a vibrancy here that’s infectious and a strong desire to do better in Research Software. That Sheffield won 2 of the 7 Research Software Engineering fellowships on offer was like a dream come true. The other Sheffield RSE fellow is Paul Richmond and we’ve joined forces to provide the strongest research software service we can to The University of Sheffield.
What do you think is the role of a Research Software Engineer?
I’m going to lift the answer to this straight out of my fellowship application.
Technological development in software is more like a cliff-face than a ladder – there are many routes to the top, to a solution. Further, the cliff face is dynamic – constantly and quickly changing as new technologies emerge and decline. Determining which technologies to deploy and how best to deploy them is in itself a specialist domain, with many features of traditional research.
Researchers need empowerment and training to give them confidence with the available equipment and the challenges they face. This role, akin to that of an Alpine guide, involves support, guidance, and load carrying. When optimally performed it results in a researcher who knows what challenges they can attack alone, and where they need appropriate support. Guides can help decide whether to exploit well-trodden paths or explore new possibilities as they navigate through this dynamic environment.
These guides are highly trained, technology-centric, research-aware individuals who have a curiosity driven nature dedicated to supporting researchers by forging a research software support career. Such Research Software Engineers (RSEs) guide researchers through the technological landscape and form a human interface between scientist and computer. A well-functioning RSE group will not just add to an organisation’s effectiveness, it will have a multiplicative effect since it will make every individual researcher more effective. It has the potential to improve the quality of research done across all University departments and faculties.
Are there any downsides to being a Research Software Engineer?
Something I’ve learned from conducting these interviews is that there are several different types of ‘Research Software Engineer’. We are not a ‘one size fits all’ community! I think that one thing we all have in common is that we don’t fit the normal ‘money-in, papers-out’ model of many academics. This was brought up in Louise Brown’s interview and it strongly resonates with me. This situation makes it difficult for us to follow an academic-like career path.
It is extremely difficult, for example, to get promoted as a research programmer without attempting to become something you are not. Worse, it’s difficult to simply get a permanent job! Many RSEs are on short term contracts with low salaries. In short, you get much of the grief of working in academia without any of the benefits. Little wonder, then, that many of the best in the community choose to work in industry.
An alternative path for RSEs is to work in the University IT department. It’s the path that I took for example. This solves the short term contract issue but brings with it a whole new set of problems. Many IT managers simply don’t understand the value that an RSE can bring to a University. You can sum the issue up with the observation ‘Academics rarely complain to the head of IT that there’s no one around who can optimise their MATLAB code but they complain very quickly when MATLAB doesn’t work on the University managed desktop’. So, guess what I’d get assigned to?
We’ve established that RSEs aren’t ‘normal academics’ and they aren’t ‘normal IT support’ either so where do we fit? I’m trying to help figure that out and help provide an environment where RSEs can not only exist but thrive.
You’ve recently won an EPSRC RSE Fellowship! Can you give a brief overview of your project?
I aim to improve the research software of the ‘long tail scientist’. This term, attributed to Jim Downing of the Unilever Centre for Molecular Informatics – refers to the large number of small research units who perform a huge amount of research. Often, these small research units only have one or two people in them. They aren’t “big science” but there are LOTS of them!
Much of this research involves the generation of code by relatively untrained and inexperienced programmers. This code can benefit greatly from input by RSEs. An experienced RSE can, with relatively little effort, significantly enhance the quality and efficiency of such code whilst simultaneously providing training for the researcher who wrote it. For examples of what I mean, see my Testiminonials page.
I will improve scientific software efficiency, sustainability and reproducibility at the University of Sheffield, by working alongside researchers on their research code in a consultative manner. Rather than working prescriptively, my approach is based on offering and implementing a series of nudges. Nudges are interventions that alter people’s behaviour in a predictable way without forbidding any options. In the context of research software, example nudges might include ‘Learn to write idiomatically in your language of choice – it can lead to faster execution’, ‘See how unit tests allow us to make changes with confidence’ or ‘Using version control, we always know which code produced what result’.
The gulf between the computing scientific “elite” and those emailing spreadsheets is growing and I aim to close that gap. One researcher I worked with recently said ‘You provide the next step after we’ve been on a Software Carpentry course.’ and I think that describes what I’m trying to do quite well.
How long did it take you to write your Fellowship application? Any other thoughts/advice on the application process?
Writing my fellowship application was one of the most difficult writing exercises I’ve ever undertaken! It took just over a month to write and during that time I did very little else. It took up my days, my evenings, my weekends, my every waking thought. It even consumed my dreams. It was exhausting!
Something that surprised me was the number of people who I needed to help make it happen. Fellowships are often made out to be very individual things but my application involved work by over 40 people! This includes university administrators at all levels, project partners, advisors and mentors. I had to navigate areas of University life and systems that were completely alien to me. There is no way I could have done it alone.
It is essential to get institutional support for your application. At the most basic level, you need a manager who is happy for you to go AWOL for a few weeks. At a higher level, you need to be able to demonstrate to the funding body that your University is fully behind you and your project.
You also need to be emotionally resilient. I poured my heart and soul into my first draft and the feedback from one of my advisors was ‘Well, you solved the blank-page problem.’ That was the only positive thing she had to say! Everything else was a tearing apart. It was brutal! I think I might have cried a little.
Every time I did a rewrite, my mentors found more weaknesses and beat up on me a little. This feedback was essential and made the application so much stronger. As such, I think one piece of advice I’d give is ‘Find mentors you trust who are going to be crushingly hard on you’. It’ll hurt but nowhere near as much as the comments of Reviewer 2 ;)
Who are your project partners?
My style of working is extremely collaborative. As such I have a lot of formal project partners: The Software Sustainability Institute, The University of Manchester, UCL, Microsoft Research, Dassault Systèmes, Wolfram Research, Mathworks, The N8 Research Partnership, Maplesoft and NAG.
Tell me about your RSE group.
Sheffield has two EPSRC RSE fellows and we’ve teamed up to form the Sheffield Research Software Engineering group. We’ve only existed for a month! At the moment its just us but we have funds to recruit a few more people so watch this space.
Which programming languages and technologies do you regularly use?
I don’t get to choose what languages I use — the researchers I support do that for me. As such, I’m doing a lot of MATLAB, Python and R these days. For compiled languages, I tend to use either C or C++. There’s also some Mathematica and Maple sprinkled here and there.
I help support Sheffield’s High Performance Computing Service so also do a reasonable amount of Bash scripting and parallel computing.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
I used to use Fortran back in the day but don’t seem to need it much now — it’s been a long time since I did a project with it. A couple of groups are offering to teach ‘Modern Fortran’ for us at Sheffield so perhaps I’ll take another look?
I used to like Perl, and even taught a one-day course on it 10 years ago but I strongly prefer Python and so, it seems, do the researchers I support.
Is there anything on your ‘to-learn’ list?
- Cloud computing: I’ve started doing some small projects using Amazon EC2 and feel very much a newbie at the moment. I can figure out how to do things but am not sure if what I am doing is good practice or not.
- Docker: I understand the basics but am yet to figure out how to use the technology properly for research.
- Julia: I played with it a little a few years ago and really like it. There’s a lot of buzz around the language. No one has come to me with a Julia problem yet but I think its just a matter of time.
- Modern OpenMP: I learned OpenMP a long time ago. It’s time for an update.
Welcome to the latest edition of A Month of Math Software where I take a look at all that is shiny and new in the computational mathematics world. This one’s slightly late and so it not only covers all of September but also the first 3 days in October. If you have any math software news that you’d like to share with the world, drop me a line and tell me all about it. Enjoy!
MATLAB gets a Ribbon (sorry…Toolstrip)
A new version of MATLAB has been released and it has had some major cosmetic surgery. The Mathworks insist on calling the new look in 2012b a Toolstrip but everyone else will call it a Ribbon. Although they’ve been around for many years, ribbon based interfaces hit the big time when Microsoft used them for Office 2007..a decision that many, many, many, many, many, many, many people hated. I hate them too and now I have to contend with one in MATLAB…and so do you because there is no way to switch back to the old interface. The best you can do is minimise the thing and pretend it doesn’t exist. Unhappy users abound (check out the user comments at http://blogs.mathworks.com/loren/2012/09/12/the-matlab-r2012b-desktop-part-1-introduction-to-the-toolstrip/ for example). There have been a lot of other changes too which I’ll discuss in an upcoming review.
Do you use MATLAB? How do you feel about this new look?
Numerical Javascript!
- Numeric, a comprehensive free numerical library for Javascript, has seen a minor update to version 1.2.3. The new release includes a much faster algorithm for linear programming.
Free and open source general purpose mathematics
- Scilab, arguably the best open source MATLAB clone available, has seen a major upgrade to version 5.4. Go to http://www.scilab.org/products/scilab/download/5.4.0/whatsnew for the new goodness.

- On 8th September, Sage version 5.3 was released. Sage is an extremely powerful general purpose mathematics package based on Python and dozens of other open source projects. The Sage development team like to say that instead of re-inventing the wheel they built a car! Mighty fine one too if you ask me. What’s new in Sage 5.3
- René Grothmann has updated his very nice, free Euler Math Toolbox. At the time of writing its at version 18.8 but the updates come thick and fast. The latest changes are always at http://euler.rene-grothmann.de/Programs/XX%20-%20Changes.html
The theory of numbers
- Pari version 2.5.3 has been released. Pari is a free ‘computer algebra system designed for fast computations in number theory’
- Magma version 2.18-10 was released in September. Magma is a commercial system for algebra, number theory, algebraic geometry and algebraic combinatorics.
Numerical Libraries
- The Intel Math Kernel Library (MKL) is now at version 11.0. The MKL is a highly optimised numerical library for Intel platforms that covers subjects such as linear algebra, fast fourier transforms and random numbers. Find out what’s new at http://software.intel.com/en-us/articles/whats-new-in-intel-mkl/
- LAPACK, the standard library for linear algebra on which libraries such as MKL and ACML are based, has been updated to version 3.4.2. There is no new functionality, this is a bug-fix release
- The Numerical Algorithms Group (NAG) have released a major update to their commercial C library. Mark 23 of the library includes lots of new stuff (345 new functions) such as a version of the Mersenne Twister random number generator with skip-ahead, additional functions for multidimensional integrals, a new suite of functions for solving boundary-value problems by an implementation of the Chebyshev pseudospectral method and loads more. The press release is at http://www.nag.co.uk/numeric/CL/newatmark23 and the juicy detail is at http://www.nag.co.uk/numeric/CL/nagdoc_cl23/html/genint/news.html
Python
- After the publication of the last Month of Math Software I learned about the death of John Hunter, author of matplotlib, due to complications arising from cancer treatment. A tribute has been written by Fernando Perez. My heart goes out to his family and friends.
- After 8 months work, version 0.11 of SciPy is now available. Go to http://docs.scipy.org/doc/scipy/reference/release.0.11.0.html for the good stuff which includes improvements to the optimisation routines and new routines for dense and sparse matrices among others.
- A new major release of pandas is available. Pandas provides easy-to-use data structures and data analysis tools for Python. See what’s new in 0.9.0 at http://pandas.pydata.org/pandas-docs/dev/whatsnew.html
Bits of this and that
- IDL version has been bumped to version 8.2.1. http://idldatapoint.com/2012/10/03/idl-8-2-1-released/ has the details.
- Gnumeric version 1.11.6 – A free spreadsheet program
And finally….
I am a big fan of the xkcd webcomic and so a recent question on the Mathematica StackExchange site instantly caught my eye. Xkcd often publishes hand drawn graphs that look like this:
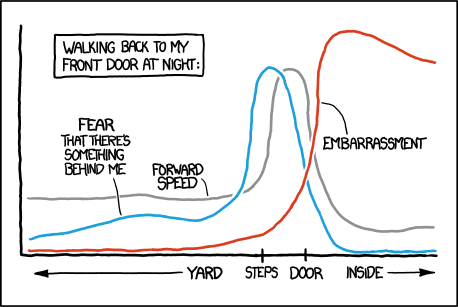
The question asked…How could one produce graphs that look like this using Mathematica? It didn’t take long before the community came up with some code that automatically produces plots like this
I am definitely going to use style in my next presentation! Not to be out-done, others have since done similar work in R, MATLAB and Latex.
One of my hobbies is retro video games and tonight’s opening ceremony for the 2012 Olympics inspired me to take a look at Olympic video games over my lifetime. Where games were released on multiple platforms I’ve simply chosen the one that was most relevant to me.
Video Olympics (Atari VCS2600, 1977)
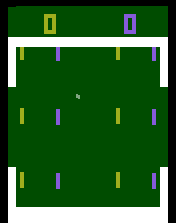
Released in the year of my birth, the Atari VCS-2600 holds a special place in my heart. The hardware was incredibly primitive and yet some of the games were surprisingly playable. I must have spent weeks of my childhood playing Combat for instance. Sadly,Video Olympics is one of the less playable games for the 2600 and should really be renamed ‘Variations on the theme of Pong.’
Hyper Sports (Arcade, 1984)
One of my abiding memories of the early 80s was spending Sunday afternoons in the children’s room of our village’s local pub. This particular village pub was a geek child’s paradise as the kids room included up to 3 arcade games at any one time. My brother and I would be given 20p each to play on these games, a sum of money that would be expected to last us at least an hour, while dad enjoyed a quiet pint in the bar.
I remember Konami’s Hyper Sports very clearly and the youtube above brings back a flood of memories for me. Hyper Sports was released in time for the 1984 Los Angeles Olympics and was the sequel to Konami’s superb Track and Field.
Micro Olympics (BBC Micro, 1984)
If you had walked into any UK primary school in the early 80s you’d have found a BBC Micro, an 8 bit computer developed by Acorn Computers (the guys who went on to develop the ARM processor used in the vast majority of mobile devices). My primary school had exactly one of these high powered beasts and each pupil only got a few minutes on it a month on average. I remember that my dad had a chat with the head master though and scored me a lot of extra time on it. As long as I didn’t make any noise whatsoever, I could use the computer just outside the headmasters office for an hour after school and I used the time to work through my collection of Marshall Cavendish Input magazines. Happy days.
The BBC wasn’t known for its games however. Micro Olympics was rubbish!
Daley Thompson’s Olympic Challenge (Sinclair Spectrum, 1988)
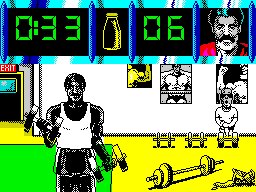
Ahhh the humble speccy— Oh how I loved thee! The spectrum was my first ‘proper’ computer and I received it for my 8th birthday. All I wanted to do was play games but my father insisted that I also learn how to program it and so I probably owe my career to dear old dad and Sinclair’s 48K wonder.
Released in time for the 1988 Seoul Olympics, Daley Thompson’s Olympic Challenge was a joystick waggler pure and simple. The game included several events: 100 metres, Long Jump, Shot Putt, High Jump and 400 metres, 110 metres Hurdles, Discus, Pole Vault, Javelin and 1500 metres but gameplay consisted of nothing more than frantically waggling your joystick side to side and occasionally pressing the fire button.
Olympic Gold (Sega MegaDrive, 1992)
I remember reading articles that previewed Sega’s megadrive. Back then its power seemed nothing short of astonishing but, sadly, I didn’t have one. One of my friends, however, did have one and many a happy hour was spent over at his house playing Mortal Kombat and Sonic the Hedgehog.
Olympic gold was the first officially licensed Olympic video game and was released in time for the Barcelona Olympics. Although the graphics are much better than older games, the game mechanic is essentially exactly the same, mash buttons as fast as you can.
1996 and beyond
By the time the 1996 Atlanta games came around, I had better things to do than play video games. That summer was my last before starting my undergraduate studies in theoretical physics. Many Olympic video games have since been released of course but I haven’t played them and neither do I want to.
So, I’ll hand over to The Complete History of Official Olympic Video Games which picks up where I left off.
Back in May 2010, The Mathworks released MATLAB Mobile which allows you to connect to a remote MATLAB session via an iPhone. I took a quick look and was less than impressed since what I REALLY wanted was the ability to run MATLAB code natively on my phone. Many other people, however, liked what The Mathworks had done but what THEY really wanted was an Android version. There is so much demand for an Android version of MATLAB Mobile that there is even a Facebook page campaigning for it. Will there ever be anything MATLABy that fully satisfies Android toting geeks such as me?
Enter Addi, an Android based MATLAB/Octave clone that has the potential to please a lot of people, including me. Based on the Java MATLAB library, JMathLib, Addi already has a lot going for it including the ability to execute .m file scripts and functions natively on your device, basic plotting (via an add-on package called AddiPlot) and the rudimentary beginnings of a toolbox system (See AddiMappingPackage). All of this is completely free and brought to us by just one man, Corbin Champion.

It works pretty well on my Samsung Galaxy S apart from the occasional glitch where I can’t see what I’m typing for short periods of time. Writing MATLAB code using the standard Android keyboard is also a bit of a pain but I believe that a custom on-screen keyboard is in the works which will hopefully improve things. As you might expect, there is only a limited subset of MATLAB commands available (essentially everything listed at http://www.jmathlib.de/docs/handbook/index.php sans the plotting functions) but there is enough to be fun and useful…just don’t expect to be able to run advanced, toolbox heavy codes straight out of the box.
Where Addi really shines, however, is on an ASUS EEE Transformer. Sadly, I don’t have one but a friend of mine let me install Addi on his and after five minutes of playing around I was in love (It even includes command history!). Some have pointed out to me that life would probably be easier with a netbook running Linux and Octave but where’s the fun in that :) To be honest, I actually find it much more fun using a limited version of MATLAB because it makes me do so much more myself rather than providing a function for every conceivable calculation…great for learning and fiddling around.
Addi is a fantastic free MATLAB clone for Android based devices that I would heartily recommend to all MATLAB fans. Get it, try it and let me know what you think :)
This little corner of the web that I like to call home has been online for 4 years as of today. I’d like to thank everyone who reads and comments on the stuff I put up here, I hope you find my wanderings interesting and/or useful.
I’d also like to thank all of the people and organisations I have collaborated with over the years while writing articles here. I’m not going to mention names out of fear of missing someone out but you know who you are. The only exception would be Matthew Haworth of Reason Digital who talked me into starting this up during his University of Manchester farewell party. He also provides me with web hosting (surviving three slashdottings so far), technical support and, on occasion, lunch! Without Matt, there would be no Walking Randomly.
Back on WRs first birthday I gave out some stats (143 RSS subscribers and 250 visits per day) and so I’ll so the same today (1645 RSS subscribers and 800 unique visits per day)
Finally, here is a list of some of my favourite articles from over the last 4 years. I hope you enjoy reading them as much as I enjoyed writing them
- Secret Messages hidden inside equations – When an equation literally spoke to me.
- The Valentine’s equations – Hearts and flowers, wrapped up in equations
- Now thats what I CALL Retro Computing – Ever wondered how easy it would be to program a 60 year old computer? Now’s your chance
- Simulating Harmonographs – Pretty pictures from pendulums
- Proof I have a brain – When I blagged my way to a free brain scan
- Should Fortran be taught to undergraduates? – My first Slashdotting. This post has been read by tens of thousands of people.
- Wheels on Wheels on Wheels – More pretty patterns
- The unreasonable ineffectiveness of factoring – We drill and kill the technique of factoring equations in schools. A pity that its useless then!
- Polygonal numbers on quadratic number spirals – Yet more pretty patterns
- Math on iPad #1 – The beginning of a series that is still ongoing
- Quadraflakes, Pentaflakes, Hexaflakes and more – Playing with a particular kind of Fractal
- Complex Power Towers – recreations in the complex plane