
Archive for the ‘CUDA’ Category
Ever since I took a look at GPU accelerating simple Monte Carlo Simulations using MATLAB, I’ve been disappointed with the performance of its GPU random number generator. In MATLAB 2012a, for example, it’s not much faster than the CPU implementation on my GPU hardware. Consider the following code
function gpuRandTest2012a(n)
mydev=gpuDevice();
disp('CPU - Mersenne Twister');
tic
CPU = rand(n);
toc
sg = parallel.gpu.RandStream('mrg32k3a','Seed',1);
parallel.gpu.RandStream.setGlobalStream(sg);
disp('GPU - mrg32k3a');
tic
Rg = parallel.gpu.GPUArray.rand(n);
wait(mydev);
toc
Running this on MATLAB 2012a on my laptop gives me the following typical times (If you try this out yourself, the first run will always be slower for various reasons I’ll not go into here)
>> gpuRandTest2012a(10000) CPU - Mersenne Twister Elapsed time is 1.330505 seconds. GPU - mrg32k3a Elapsed time is 1.006842 seconds.
Running the same code on MATLAB 2012b, however, gives a very pleasant surprise with typical run times looking like this
CPU - Mersenne Twister Elapsed time is 1.590764 seconds. GPU - mrg32k3a Elapsed time is 0.185686 seconds.
So, generation of random numbers using the GPU is now over 7 times faster than CPU generation on my laptop hardware–a significant improvment on the previous implementation.
New generators in 2012b
The MATLAB developers went a little further in 2012b though. Not only have they significantly improved performance of the mrg32k3a combined multiple recursive generator, they have also implemented two new GPU random number generators based on the Random123 library. Here are the timings for the generation of 100 million random numbers in MATLAB 2012b
- Get the code – gpuRandTest2012b.m
CPU - Mersenne Twister Elapsed time is 1.370252 seconds. GPU - mrg32k3a Elapsed time is 0.186152 seconds. GPU - Threefry4x64-20 Elapsed time is 0.145144 seconds. GPU - Philox4x32-10 Elapsed time is 0.129030 seconds.
Bear in mind that I am running this on the relatively weak GPU of my laptop! If anyone runs it on something stronger, I’d love to hear of your results.
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit.
- MATLAB: 2012a/2012b
Intel have finally released the Xeon Phi – an accelerator card based on 60 or so customised Intel cores to give around a Teraflop of double precision performance. That’s comparable to the latest cards from NVIDIA (1.3 Teraflops according to http://www.theregister.co.uk/2012/11/12/nvidia_tesla_k20_k20x_gpu_coprocessors/) but with one key difference—you don’t need to learn any new languages or technologies to take advantage of it (although you can do so if you wish)!
The Xeon Phi uses good, old fashioned High Performance Computing technologies that we’ve been using for years such as OpenMP and MPI. There’s no need to completely recode your algorithms in CUDA or OpenCL to get a performance boost…just a sprinkling of OpenMP pragmas might be enough in many cases. Obviously it will take quite a bit of work to squeeze every last drop of performance out of the thing but this might just be the realisation of ‘personal supercomputer’ we’ve all been waiting for.
Here are some links I’ve found so far — would love to see what everyone else has come up with. I’ll update as I find more
- http://www.theregister.co.uk/2012/11/12/intel_xeon_phi_coprocessor_launch/ (Includes pricing and some benchmarks)
- http://www.streamcomputing.eu/blog/2012-11-12/intels-answer-to-amd-and-nvidia-the-xeon-phi-5110p/ (lots of details, programming models and comparisons with GPUs)
- http://software.intel.com/en-us/blogs/2012/11/12/introducing-opencl-12-for-intel-xeon-phi-coprocessor (Intel’s OpenCL works on Xeon Phi)
- http://www.hpcwire.com/hpcwire/2012-11-12/nag_delivers_numerical_software_to_xeon_phi.html (My favourite numerical library has already been ported to the Phi)
I also note that the Xeon Phi uses AVX extensions but with a wider vector width of 512 bytes so if you’ve been taking advantage of that technology in your code (using one of these techniques perhaps) you’ll reap the benefits there too.
I, for one, am very excited and can’t wait to get my hands on one! Thoughts, comments and links gratefully received!
Updated 26th March 2015
I’ve been playing with AVX vectorisation on modern CPUs off and on for a while now and thought that I’d write up a little of what I’ve discovered. The basic idea of vectorisation is that each processor core in a modern CPU can operate on multiple values (i.e. a vector) simultaneously per instruction cycle.
Modern processors have 256bit wide vector units which means that each CORE can perform up to 16 double precision or 32 single precision floating point operations (FLOPS) per clock cycle. So, on a quad core CPU that’s typically found in a decent laptop you have 4 vector units (one per core) and could perform up to 64 double precision FLOPS per cycle. The Intel Xeon Phi accelerator unit has even wider vector units — 512bit!
This all sounds great but how does a programmer actually make use of this neat hardware trick? There are many routes:-
Intrinsics
At the ‘close to the metal’ level you code for these vector units using instructions called AVX intrinsics. This is relatively difficult and leads to none-portable code if you are not careful.
- The Intel Intrinsics Guide – An interactive reference tool for Intel intrinsic instructions,
- Introduction to Intel Advanced Vector Extensions – includes some example C++ programs using AVX intinsics
- Benefits of Intel AVX for small matrices – More code examples along with speed comparisons.
Auto-vectorisation in compilers
Since working with intrinsics is such hard work, why not let the compiler take the strain? Many modern compilers can automatically vectorize your C, C++ or Fortran code including gcc, PGI and Intel. Sometimes all you need to do is add an extra switch at compile time and reap the speed benefits. In truth, vectorization isn’t always automatic and the programmer needs to give the compiler some assistance but it is a lot easier than hand-coding intrinsics.
- A Guide to Auto-vectorization with Intel C++ Compilers – Exactly what it says. In my experience, the intel compilers do auto-vectorisation better than other compilers.
- Auto-vectorisation in gcc 4.7 – A superb article showing how auto-vectorisation works in practice when using gcc 4.7. Lots of C code examples along with the emitted assembler and a good discussion of the hints you may need to give to the compiler to get maximum performance.
- Auto-vectorisation in gcc – The project page for auto-vectorisation in gcc
- Optimizing Application Performance on x64 Processor-based Systems with PGI Compilers and Tools – Includes discussion and example of auto-vectorisation using the PGI compiler
- Jim Radigan: Inside Auto-Vectorization, 1 of n – A video by a Microsoft engineer working on Visual Studio 2012. A superb introduction to what vectorisation is along with speed-up demonstrations and discussion on how the auto-vectoriser will work in Visual Studio 2012.
- Auto Vectorizer in Visual Studio 2012 – A series of blog articles about vectorization in Visual Studio 2012.
Intel SPMD Program Compiler (ispc)
There is a midway point between automagic vectorisation and having to use intrinsics. Intel have a free compiler called ispc (http://ispc.github.com/) that allows you to write compute kernels in a modified subset of C. These kernels are then compiled to make use of vectorised instruction sets. Programming using ispc feels a little like using OpenCL or CUDA. I figured out how to hook it up to MATLAB a few months ago and developed a version of the Square Root function that is almost twice as fast as MATLAB’s own version for sandy bridge i7 processors.
- http://ispc.github.com/ – The website for ispc
- http://ispc.github.com/perf.html – Some performance metrics. In some cases combining vectorisation and parallelisation can increase single precision throughput by more than a factor of 32 on a quad-core machine!
- ispc: A SPMD Compiler For High-Performance CPU Programming, Illinois-Intel Parallelism Center Distinguished Speaker Series (UIUC), March 15, 2012. (talk video–requires Windows Media Player.) This link was taken from Matt Pharr’s website (The author of ispc).
OpenMP
OpenMP is an API specification for parallel programming that’s been supported by several compilers for many years. OpenMP 4 was released in mid 2013 and included support for vectorisation.
- Performance Essentials with OpenMP 4.0 Vectorization – A series of seven videos from Intel covering performance essentials using OpenMP 4.0 Vectorization with C/C++.
- Explicit Vector Programming with OpenMP 4.0 SIMD Extensions – A tutorial from HPC today.
Vectorised Libraries
Vendors of numerical libraries are steadily applying vectorisation techniques in order to maximise performance. If the execution speed of your application depends upon these library functions, you may get a significant speed boost simply by updating to the latest version of the library and recompiling with the relevant compiler flags.
- Yeppp! – A fast, vectorised math library (benchmarks here)
- NAG Library for Xeon Phi – A huge, commercial library for the Intel Xeon Phi Accelerator
- Intel AVX optimization in Intel Math Kernel Library (MKL) – See what’s been vectorised in version 10.3 of the MKL
- Intel Integrated Performance Primitives (IPP) Functions Optimized for AVX – The IPP library includes many basic algorithms used in image and signal processing
- SIMD Library for Evaluating Elementary Functions (SLEEF) – An open-source, vectorised library for the calculation of various mathematical functions. Someone has done benchmarks for it here.
- SIMD-oriented Fast Mersenne Twister (SFMT) – Uses vectorisation to implement a very fast random number generation.
CUDA for x86
Another route to vectorised code is to make use of the PGI Compiler’s support for x86 CUDA. What you do is take CUDA kernels written for NVIDIA GPUs and use the PGI Compiler to compile these kernels for x86 processors. The resulting executables take advantage of vectorisation. In essence, the vector units of the CPU are acting like CUDA cores–which they sort of are anyway!
The PGI compilers also have technology which they call PGI Unified binary which allows you to use NVIDIA GPUs when present or default to using multi-core x86 if no GPU is present.
- PGI CUDA-x86 – PGI’s main page for their CUDA on x86 technologies
OpenCL for x86 processors
Yet another route to vectorisation would be to use Intel’s OpenCL implementation which takes OpenCL kernels and compiles them down to take advantage of vector units (http://software.intel.com/en-us/blogs/2011/09/26/autovectorization-in-intel-opencl-sdk-15/). The AMD OpenCL implementation may also do this but I haven’t tried it and haven’t had chance to research it yet.
WalkingRandomly posts
I’ve written a couple of blog posts that made use of this technology.
- Using Intel’s SPMD Compiler (ispc) with MATLAB on Linux
- Using the Portland PGI Compiler for MATLAB mex files in Windows
Miscellaneous resources
There is other stuff out there but the above covers everything that I have used so far. I’ll finish by saying that everyone interested in vectorisation should check out this website…It’s the bible!
Research Articles on SSE/AVX vectorisation
I found the following research articles useful/interesting. I’ll add to this list over time as I dig out other articles.
After writing my recent article on GPU accelerated Matrix-Matrix multiplication using Maple, I thought that I’d try the same thing in Mathematica. However, I instantly hit a problem on my 64bit Windows 7 machine running version 8.0.1 of Mathematica.
In[1]:= a = RandomReal[1, {2, 2}]
Out[1]= {{0.363441, 0.528656}, {0.208881, 0.510232}}
In[2]:= b = RandomReal[1, {2, 2}]
Out[2]= {{0.33536, 0.77615}, {0.537533, 0.788522}}
In[3]:= Dot[a, b]
Out[3]= {{0.406054, 0.698942}, {0.344317, 0.564452}}
In[4]:= Needs["CUDALink`"]
CUDADot[a, b]
Out[5]= {{0.741414, 1.47509}, {0.881849, 1.35297}}
In short, CUDADot gives the wrong result for floating point numbers (on my machine at least). An upgrade to version 8.0.4 fixed the problem
Maple has had support for NVidia GPUs since version 14 but I’ve not played with it much until recently. Essentially I was put off by the fact that Maple’s CUDA package seemed to have support for only one function – Matrix-Matrix Multiplication. However, a recent conversation with a Maple developer changed my mind.
It is true that only MatrixMatrixMultiply has been accelerated but when you flip the CUDA switch in Maple, every function in the LinearAlgebra package that calls MatrixMatrixMultiply also gets accelerated. This leads to the possibility of a lot of speed-ups for very little work.
So, this morning I thought I would take a closer look using my laptop. Let’s start by timing how long it takes the CPU to multiply two 4000 by 4000 double precision matrices
with(LinearAlgebra): CUDA:-Enable(false): CUDA:-IsEnabled(); a := RandomMatrix(4000, datatype = float[8]): b := RandomMatrix(4000, datatype = float[8]): t := time[real](): c := a.b: time[real]()-t
The exact time varied a little from run to run but 3.76 seconds is a typical result. I’m only feeling my way at this stage so not doing any proper benchmarking.
To do this calculation on the GPU, all I need to do is change the line
CUDA:-Enable(false):
to
CUDA:-Enable(true):
like so
with(LinearAlgebra): CUDA:-Enable(true): CUDA:-IsEnabled(); a := RandomMatrix(4000, datatype = float[8]): b := RandomMatrix(4000, datatype = float[8]): t := time[real](): c := a.b: time[real]()-t
Typical execution time was 8.37 seconds so the GPU version is more than 2 times slower than the CPU version on my machine.
Trying different matrix sizes
Not wanting to admit defeat after just a single trial, I timed the above code using different matrix sizes. Here are the results
- 1000 by 1000: CPU=0.07 seconds GPU=0.17 seconds
- 2000 by 2000: CPU=0.53 seconds GPU=1.07 seconds
- 4000 by 4000: CPU=3.76 seconds GPU=8.37 seconds
- 5000 by 5000: CPU=7.44 seconds GPU=19.48 seconds
Switching to single precision
GPUs do much better with single precision numbers so I had a try with those too. All you need to do is change
datatype = float[8]
to
datatype = float[4]
in the above code. The results are:
- 1000 by 1000: CPU=0.03 seconds GPU=0.07 seconds
- 2000 by 2000: CPU=0.35 seconds GPU=0.66 seconds
- 4000 by 4000: CPU=1.86 seconds GPU=2.37 seconds
- 5000 by 5000: CPU=3.81 seconds GPU=5.2 seconds
So the GPU loses in single precision mode too on my hardware. If I can’t get a speedup with MatrixMatrixMultiply on my system then there is no point in exploring all of the other LinearAlgebra routines since all of them will be slower when moving to CUDA acceleration.
I guess that in this case, my CPU is too powerful and my GPU is too wimpy to see the acceleration I was hoping for.
Thanks to Maplesoft for providing me with a review copy of Maple 15.
Test System Specification
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit.
- Maple 15
This article is the second part of a series where I look at rewriting a particular piece of MATLAB code using various techniques. The introduction to the series is here and the introduction to the larger series of GPU articles for MATLAB on WalkingRandomly is here.
Attempt 1 – Make as few modifications as possible
I took my best CPU-only code from last time (optimised_corr2.m) and changed a load of data-types from double to gpuArray in order to get the calculation to run on my laptop’s GPU using the parallel computing toolbox in MATLAB 2010b. I also switched to using the GPU versions of various functions such as parallel.gpu.GPUArray.randn instead of randn for example. Functions such as cumprod needed no modifications at all since they are nicely overloaded; if the argument to cumprod is of type double then the calculation happens on the CPU whereas if it is gpuArray then it happens on the GPU.
The above work took about a minute to do which isn’t bad for a CUDA ‘porting’ effort! The result, which I’ve called GPU_PCT_corr1.m is available for you to download and try out.
How about performance? Let’s do a quick tic and toc using my laptop’s NVIDIA GT 555M GPU.
>> tic;GPU_PCT_corr1;toc Elapsed time is 950.573743 seconds.
The CPU version of this code took only 3.42 seconds which means that this GPU version is over 277 times slower! Something has gone horribly, horribly wrong!
Attempt 2 – Switch from script to function
In general functions should be faster than scripts in MATLAB because more automatic optimisations are performed on functions. I didn’t see any difference in the CPU version of this code (see optimised_corr3.m from part 1 for a CPU function version) and so left it as a script (partly so I had an excuse to discuss it here if I am honest). This GPU-version, however, benefits noticeably from conversion to a function. To do this, add the following line to the top of GPU_PCT_corr1.m
function [SimulPrices] = GPU_PTC_corr2( n,sub_size)
Next, you need to delete the following two lines
n=100000; %Number of simulations sub_size = 125;
Finally, add the following to the end of our new function
end
That’s pretty much all I did to get GPU_PCT_corr2.m. Let’s see how that performs using the same parameters as our script (100,000 simulations in blocks of 125). I used script_vs_func.m to run both twice after a quick warm-up iteration and the results were:
Warm up Elapsed time is 1.195806 seconds. Main event script Elapsed time is 950.399920 seconds. function Elapsed time is 938.238956 seconds. script Elapsed time is 959.420186 seconds. function Elapsed time is 939.716443 seconds.
So, switching to a function has saved us a few seconds but performance is still very bad!
Attempt 3 – One big matrix multiply!
So far all I have done is take a program that works OK on a CPU, and run it exactly as-is on the GPU in the hope that something magical would happen to make it go faster. Of course, GPUs and CPUs are very different beasts with differing sets of strengths and weaknesses so it is rather naive to think that this might actually work. What we need to do is to play to the GPUs strengths more and the way to do this is to focus on this piece of code.
for i=1:sub_size
CorrWiener(:,:,i)=parallel.gpu.GPUArray.randn(T-1,2)*UpperTriangle;
end
Here, we are performing lots of small matrix multiplications and, as mentioned in part 1, we might hope to get better performance by performing just one large matrix multiplication instead. To do this we can change the above code to
%Generate correlated random numbers
%using one big multiplication
randoms = parallel.gpu.GPUArray.randn(sub_size*(T-1),2);
CorrWiener = randoms*UpperTriangle;
CorrWiener = reshape(CorrWiener,(T-1),sub_size,2);
%CorrWiener = permute(CorrWiener,[1 3 2]); %Can't do this on the GPU in 2011b or below
%poor man's permute since GPU permute if not available in 2011b
CorrWiener_final = parallel.gpu.GPUArray.zeros(T-1,2,sub_size);
for s = 1:2
CorrWiener_final(:, s, :) = CorrWiener(:, :, s);
end
The reshape and permute are necessary to get the matrix in the form needed later on. Sadly, MATLAB 2011b doesn’t support permute on GPUArrays and so I had to use the ‘poor mans permute’ instead.
The result of the above is contained in GPU_PCT_corr3.m so let’s see how that does in a fresh instance of MATLAB.
>> tic;GPU_PCT_corr3(100000,125);toc Elapsed time is 16.666352 seconds. >> tic;GPU_PCT_corr3(100000,125);toc Elapsed time is 8.725997 seconds. >> tic;GPU_PCT_corr3(100000,125);toc Elapsed time is 8.778124 seconds.
The first thing to note is that performance is MUCH better so we appear to be on the right track. The next thing to note is that the first evaluation is much slower than all subsequent ones. This is totally expected and is due to various start-up overheads.
Recall that 125 in the above function calls refers to the block size of our monte-carlo simulation. We are doing 100,000 simulations in blocks of 125– a number chosen because I determined empirically that this was the best choice on my CPU. It turns out we are better off using much larger block sizes on the GPU:
>> tic;GPU_PCT_corr3(100000,250);toc Elapsed time is 6.052939 seconds. >> tic;GPU_PCT_corr3(100000,500);toc Elapsed time is 4.916741 seconds. >> tic;GPU_PCT_corr3(100000,1000);toc Elapsed time is 4.404133 seconds. >> tic;GPU_PCT_corr3(100000,2000);toc Elapsed time is 4.223403 seconds. >> tic;GPU_PCT_corr3(100000,5000);toc Elapsed time is 4.069734 seconds. >> tic;GPU_PCT_corr3(100000,10000);toc Elapsed time is 4.039446 seconds. >> tic;GPU_PCT_corr3(100000,20000);toc Elapsed time is 4.068248 seconds. >> tic;GPU_PCT_corr3(100000,25000);toc Elapsed time is 4.099588 seconds.
The above, rather crude, test suggests that block sizes of 10,000 are the best choice on my laptop’s GPU. Sadly, however, it’s STILL slower than the 3.42 seconds I managed on the i7 CPU and represents the best I’ve managed using pure MATLAB code. The profiler tells me that the vast majority of the GPU execution time is spent in the cumprod line and in random number generation (over 40% each).
Trying a better GPU
Of course now that I have code that runs on a GPU I could just throw it at a better GPU and see how that does. I have access to MATLAB 2011b on a Tesla M2070 hooked up to a Linux machine so I ran the code on that. I tried various block sizes and the best time was 0.8489 seconds with the call GPU_PCT_corr3(100000,20000) which is just over 4 times faster than my laptop’s CPU.
Ask the Audience
Can you do better using just the GPU functionality provided in the Parallel Computing Toolbox (so no bespoke CUDA kernels or Jacket just yet)? I’ll be looking at how AccelerEyes’ Jacket myself in the next post.
Results so far
- Best CPU Result on laptop (i7-2630GM)with pure MATLAB code – 3.42 seconds
- Best GPU Result with PCT on laptop (GT555M) – 4.04 seconds
- Best GPU Result with PCT on Tesla M2070 – 0.85 seconds
Test System Specification
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit.
- MATLAB: 2011b
Acknowledgements
Thanks to Yong Woong Lee of the Manchester Business School as well as various employees at The Mathworks for useful discussions and advice. Any mistakes that remain are all my own :)
This is part 2 of an ongoing series of articles about MATLAB programming for GPUs using the Parallel Computing Toolbox. The introduction and index to the series is at https://www.walkingrandomly.com/?p=3730. All timings are performed on my laptop (hardware detailed at the end of this article) unless otherwise indicated.
Last time
In the previous article we saw that it is very easy to run MATLAB code on suitable GPUs using the parallel computing toolbox. We also saw that the GPU has its own area of memory that is completely separate from main memory. So, if you have a program that runs in main memory on the CPU and you want to accelerate part of it using the GPU then you’ll need to explicitly transfer data to the GPU and this takes time. If your GPU calculation is particularly simple then the transfer times can completely swamp your performance gains and you may as well not bother.
So, the moral of the story is either ‘Keep data transfers between GPU and host down to a minimum‘ or ‘If you are going to transfer a load of data to or from the GPU then make sure you’ve got a ton of work for the GPU to do.‘ Today, I’m going to consider the latter case.
A more complicated elementwise function – CPU version
Last time we looked at a very simple elementwise calculation– taking the sine of a large array of numbers. This time we are going to increase the complexity ever so slightly. Consider trig_series.m which is defined as follows
function out = myseries(t) out = 2*sin(t)-sin(2*t)+2/3*sin(3*t)-1/2*sin(4*t)+2/5*sin(5*t)-1/3*sin(6*t)+2/7*sin(7*t); end
Let’s generate 75 million random numbers and see how long it takes to apply this function to all of them.
cpu_x = rand(1,75*1e6)*10*pi; tic;myseries(cpu_x);toc
I did the above calculation 20 times using a for loop and took the median of the results to get 4.89 seconds1. Note that this calculation is fully parallelised…all 4 cores of my i7 CPU were working on the problem simultaneously (Many built in MATLAB functions are parallelised these days by the way…No extra toolbox necessary).
GPU version 1 (Or ‘How not to do it’)
One way of performing this calculation on the GPU would be to proceed as follows
cpu_x =rand(1,75*1e6)*10*pi; tic %Transfer data to GPU gpu_x = gpuArray(cpu_x); %Do calculation using GPU gpu_y = myseries(gpu_x); %Transfer results back to main memory cpu_y = gather(gpu_y) toc
The mean time of the above calculation on my laptop’s GPU is 3.27 seconds, faster than the CPU version but not by much. If you don’t include data transfer times in the calculation then you end up with 2.74 seconds which isn’t even a factor of 2 speed-up compared to the CPU.
GPU version 2 (arrayfun to the rescue)
We can get better performance out of the GPU simply by changing the line that does the calculation from
gpu_y = myseries(gpu_x);
to a version that uses MATLAB’s arrayfun command.
gpu_y = arrayfun(@myseries,gpu_x);
So, the full version of the code is now
cpu_x =rand(1,75*1e6)*10*pi; tic %Transfer data to GPU gpu_x = gpuArray(cpu_x); %Do calculation using GPU via arrayfun gpu_y = arrayfun(@myseries,gpu_x); %Transfer results back to main memory cpu_y = gather(gpu_y) toc
This improves the timings quite a bit. If we don’t include data transfer times then the arrayfun version completes in 1.42 seconds down from 2.74 seconds for the original GPU code. Including data transfer, the arrayfun version complete in 1.94 seconds compared to for the 3.27 seconds for the original.
Using arrayfun for the GPU is definitely the way to go! Giving the GPU every disadvantage I can think of (double precision, including transfer times, comparing against multi-thread CPU code etc) we still get a speed-up of just over 2.5 times on my laptop’s hardware. Pretty useful for hardware that was designed for energy-efficient gaming!
Note: Something that I learned while writing this post is that the first call to arrayfun will be slower than all of the rest. This is because arrayfun compiles the MATLAB function you pass it down to PTX and this can take a while (seconds). Subsequent calls will be much faster since arrayfun will use the compiled results. The compiled PTX functions are not saved between MATLAB sessions.
arrayfun – Good for your memory too!
Using the arrayfun function is not only good for performance, it’s also good for memory management. Imagine if I had 100 million elements to operate on instead of only 75 million. On my 3Gb GPU, the following code fails:
cpu_x = rand(1,100*1e6)*10*pi;
gpu_x = gpuArray(cpu_x);
gpu_y = myseries(gpu_x);
??? Error using ==> GPUArray.mtimes at 27
Out of memory on device. You requested: 762.94Mb, device has 724.21Mb free.
Error in ==> myseries at 3
out =
2*sin(t)-sin(2*t)+2/3*sin(3*t)-1/2*sin(4*t)+2/5*sin(5*t)-1/3*sin(6*t)+2/7*sin(7*t);
If we use arrayfun, however, then we are in clover. The following executes without complaint.
cpu_x = rand(1,100*1e6)*10*pi; gpu_x = gpuArray(cpu_x); gpu_y = arrayfun(@myseries,gpu_x);
Some Graphs
Just like last time, I ran this calculation on a range of input arrays from 1 million to 100 million elements on both my laptop’s GT 555M GPU and a Tesla C2050 I have access to. Unfortunately, the C2050 is running MATLAB 2010b rather than 2011a so it’s not as fair a test as I’d like. I could only get up to 84 million elements on the Tesla before it exited due to memory issues. I’m not sure if this is down to the hardware itself or the fact that it was running an older version of MATLAB.

Next, I looked at the actual speed-up shown by the GPUs compared to my laptop’s i7 CPU. Again, this includes data transfer times, is in full double precision and the CPU version was multi-threaded (No dodgy ‘GPUs are awesome’ techniques used here). No matter what array size is used I get almost a factor of 3 speed-up using the laptop GPU and more than a factor of 7 speed-up when using the Tesla. Not too shabby considering that the programming effort to achieve this speed-up was minimal.
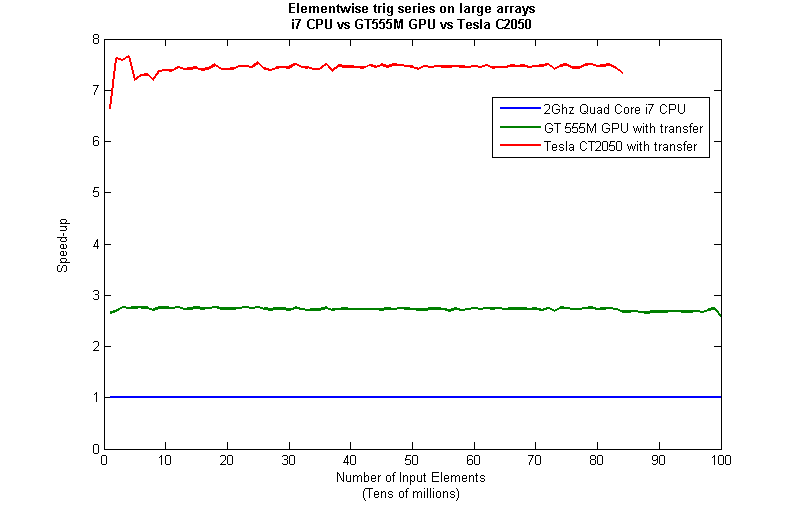
Conclusions
- It is VERY easy to modify simple, element-wise functions to take advantage of the GPU in MATLAB using the Parallel Computing Toolbox.
- arrayfun is the most efficient way of dealing with such functions.
- My laptop’s GPU demonstrated almost a 3 times speed-up compared to its CPU.
Hardware / Software used for the majority of this article
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit. I’m not using Linux because of the lack of official support for Optimus.
- MATLAB: 2011a with the parallel computing toolbox
Code and sample timings (Will grow over time)
You need myseries.m and trigseries_test.m and the Parallel Computing Toolbox. These are the times given by the following function call for various systems (transfer included and using arrayfun).
[cpu,~,~,~,gpu] = trigseries_test(10,50*1e6,'mean')
GPUs
- Tesla C2050, Linux, 2010b – 0.4751 seconds
- NVIDIA GT 555M – 144 CUDA Cores, 3Gb RAM, Windows 7, 2011a – 1.2986 seconds
CPUs
- Intel Core i7-2630QM, Windows 7, 2011a (My laptop’s CPU) – 3.33 seconds
- Intel Core 2 Quad Q9650 @ 3.00GHz, Linux, 2011a – 3.9452 seconds
Footnotes
1 – This is the method used in all subsequent timings and is similar to that used by the File Exchange function, timeit (timeit takes a median, I took a mean). If you prefer to use timeit then the function call would be timeit(@()myseries(cpu_x)). I stick to tic and toc in the article because it makes it clear exactly where timing starts and stops using syntax well known to most MATLABers.
Thanks to various people at The Mathworks for some useful discussions, advice and tutorials while creating this series of articles.
This is part 1 of an ongoing series of articles about MATLAB programming for GPUs using the Parallel Computing Toolbox. The introduction and index to the series is at https://www.walkingrandomly.com/?p=3730.
Have you ever needed to take the sine of 100 million random numbers? Me either, but such an operation gives us an excuse to look at the basic concepts of GPU computing with MATLAB and get an idea of the timings we can expect for simple elementwise calculations.
Taking the sine of 100 million numbers on the CPU
Let’s forget about GPUs for a second and look at how this would be done on the CPU using MATLAB. First, I create 100 million random numbers over a range from 0 to 10*pi and store them in the variable cpu_x;
cpu_x = rand(1,100000000)*10*pi;
Now I take the sine of all 100 million elements of cpu_x using a single command.
cpu_y = sin(cpu_x)
I have to confess that I find the above command very cool. Not only are we looping over a massive array using just a single line of code but MATLAB will also be performing the operation in parallel. So, if you have a multicore machine (and pretty much everyone does these days) then the above command will make good use of many of those cores. Furthermore, this kind of parallelisation is built into the core of MATLAB….no parallel computing toolbox necessary. As an aside, if you’d like to see a list of functions that automatically run in parallel on the CPU then check out my blog post on the issue.
So, how quickly does my 4 core laptop get through this 100 million element array? We can find out using the MATLAB functions tic and toc. I ran it three times on my laptop and got the following
>> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.833626 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.899769 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.916969 seconds.
So the first thing you’ll notice is that the timings vary and I’m not going to go into the reasons why here. What I am going to say is that because of this variation it makes sense to time the calculation a number of times (20 say) and take an average. Let’s do that
sintimes=zeros(1,20);
for i=1:20;tic;cpu_y = sin(cpu_x);sintimes(i)=toc;end
average_time = sum(sintimes)/20
average_time =
0.8011
So, on average, it takes my quad core laptop just over 0.8 seconds to take the sine of 100 million elements using the CPU. A couple of points:
- I note that this time is smaller than any of the three test times I did before running the loop and I’m not really sure why. I’m guessing that it takes my CPU a short while to decide that it’s got a lot of work to do and ramp up to full speed but further insights are welcomed.
- While staring at the CPU monitor I noticed that the above calculation never used more than 50% of the available virtual cores. It’s using all 4 of my physical CPU cores but perhaps if it took advantage of hyperthreading I’d get even better performance? Changing OMP_NUM_THREADS to 8 before launching MATLAB did nothing to change this.
Taking the sine of 100 million numbers on the GPU
Just like before, we start off by using the CPU to generate the 100 million random numbers1
cpu_x = rand(1,100000000)*10*pi;
The first thing you need to know about GPUs is that they have their own memory that is completely separate from main memory. So, the GPU doesn’t know anything about the array created above. Before our GPU can get to work on our data we have to transfer it from main memory to GPU memory and we acheive this using the gpuArray command.
gpu_x = gpuArray(cpu_x); %this moves our data to the GPU
Once the GPU can see all our data we can apply the sine function to it very easily.
gpu_y = sin(gpu_x)
Finally, we transfer the results back to main memory.
cpu_y = gather(gpu_y)
If, like many of the GPU articles you see in the literature, you don’t want to include transfer times between GPU and host then you time the calculation like this:
tic gpu_y = sin(gpu_x); toc
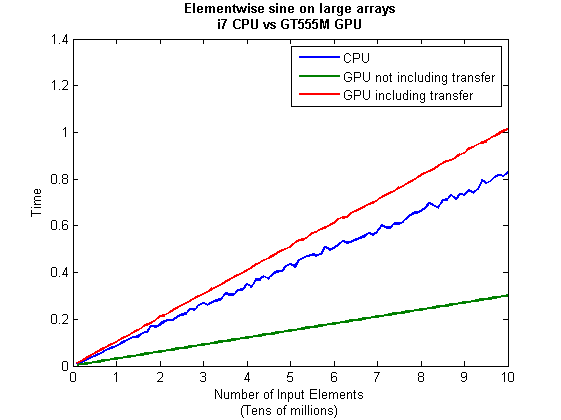
Just like the CPU version, I repeated this calculation several times and took an average. The result was 0.3008 seconds giving a speedup of 2.75 times compared to the CPU version.
If, however, you include the time taken to transfer the input data to the GPU and the results back to the CPU then you need to time as follows
tic gpu_x = gpuArray(cpu_x); gpu_y = sin(gpu_x); cpu_y = gather(gpu_y) toc
On my system this takes 1.0159 seconds on average– longer than it takes to simply do the whole thing on the CPU. So, for this particular calculation, transfer times between host and GPU swamp the benefits gained by all of those CUDA cores.
Benchmark code
I took the ideas above and wrote a simple benchmark program called sine_test. The way you call it is as follows
[cpu,gpu_notransfer,gpu_withtransfer] = sin_test(numrepeats,num_elements]
For example, if you wanted to run the benchmarks 20 times on a 1 million element array and return the average times then you just do
>> [cpu,gpu_notransfer,gpu_withtransfer] = sine_test(20,1e6)
cpu =
0.0085
gpu_notransfer =
0.0022
gpu_withtransfer =
0.0116
I then ran this on my laptop for array sizes ranging from 1 million to 100 million and used the results to plot the graph below.
But I wanna write a ‘GPUs are awesome’ paper
So far in this little story things are not looking so hot for the GPU and yet all of the ‘GPUs are awesome’ papers you’ve ever read seem to disagree with me entirely. What on earth is going on? Well, lets take the advice given by csgillespie.wordpress.com and turn it on its head. How do we get awesome speedup figures from the above benchmarks to help us pump out a ‘GPUs are awesome paper’?
0. Don’t consider transfer times between CPU and GPU.
We’ve already seen that this can ruin performance so let’s not do it shall we? As long as we explicitly say that we are not including transfer times then we are covered.
1. Use a singlethreaded CPU.
Many papers in the literature compare the GPU version with a single-threaded CPU version and yet I’ve been using all 4 cores of my processor. Silly me…let’s fix that by running MATLAB in single threaded mode by launching it with the command
matlab -singleCompThread
Now when I run the benchmark for 100 million elements I get the following times
>> [cpu,gpu_no,gpu_with] = sine_test(10,1e8)
cpu =
2.8875
gpu_no =
0.3016
gpu_with =
1.0205
Now we’re talking! I can now claim that my GPU version is over 9 times faster than the CPU version.
2. Use an old CPU.
My laptop has got one of those new-fangled sandy-bridge i7 processors…one of the best classes of CPU you can get for a laptop. If, however, I was doing these tests at work then I guess I’d be using a GPU mounted in my university Desktop machine. Obviously I would compare the GPU version of my program with the CPU in the Desktop….an Intel Core 2 Quad Q9650. Heck its running at 3Ghz which is more Ghz than my laptop so to the casual observer (or a phb) it would look like I was using a more beefed up processor in order to make my comparison fairer.
So, I ran the CPU benchmark on that (in singleCompThread mode obviously) and got 4.009 seconds…noticeably slower than my laptop. Awesome…I am definitely going to use that figure!
I know what you’re thinking…Mike’s being a fool for the sake of it but csgillespie.wordpress.com puts it like this ‘Since a GPU has (usually) been bought specifically for the purpose of the article, the CPU can be a few years older.’ So, some of those ‘GPU are awesome’ articles will be accidentally misleading us in exactly this manner.
3. Work in single precision.
Yeah I know that you like working with double precision arithmetic but that slows GPUs down. So, let’s switch to single precision. Just argue in your paper that single precision is OK for this particular calculation and we’ll be set. To change the benchmarking code all you need to do is change every instance of
rand(1,num_elems)*10*pi;
to
rand(1,num_elems,'single')*10*pi;
Since we are reputable researchers we will, of course, modify both the CPU and GPU versions to work in single precision. Timings are below
- Desktop at work (single thread, single precision): 3.49 seconds
- Laptop GPU (single precision, not including transfer): 0.122 seconds
OK, so switching to single precision made the CPU version a bit faster but it’s more than doubled GPU performance. We can now say that the GPU version is over 28 times faster than the CPU version. Now we have ourselves a bone-fide ‘GPUs are awesome’ paper.
4. Use the best GPU we can find
So far I have been comparing the CPU against the relatively lowly GPU in my laptop. Obviously, however, if I were to do this for real then I’d get a top of the range Tesla. It turns out that I know someone who has a Tesla C2050 and so we ran the single precision benchmark on that. The result was astonishing…0.0295 seconds for 100 million numbers not including transfer times. The double precision performance for the same calculation on the C2050 was 0.0524 seonds.
5. Write the abstract for our ‘GPUs are awesome’ paper
We took an Nvidia Tesla C2050 GPU and mounted it in a machine containing an Intel Quad Core CPU running at 3Ghz. We developed a program that performs element-wise trigonometry on arrays of up to 100 million single precision random numbers using both the CPU and the GPU. The GPU version of our code ran up to 118 times faster than the CPU version. GPUs are awesome!
Results from different CPUs and GPUs. Double precision, multi-threaded
I ran the sine_test benchmark on several different systems for 100 million elements. The CPU was set to be multi-threaded and double precision was used throughout.
sine_test(10,1e8)
GPUs
- Tesla C2050, Linux, 2011a – 0.7487 seconds including transfers, 0.0524 seconds excluding transfers.
- GT 555M – 144 CUDA Cores, 3Gb RAM, Windows 7, 2011a (My laptop’s GPU) -1.0205 seconds including transfers, 0.3016 seconds excluding transfers
CPUs
- Intel Core i7-880 @3.07Ghz, Linux, 2011a – 0.659 seconds
- Intel Core i7-2630QM, Windows 7, 2011a (My laptop’s CPU) – 0.801 seconds
- Intel Core 2 Quad Q9650 @ 3.00GHz, Linux – 0.958 seconds
Conclusions
- MATLAB’s new GPU functions are very easy to use! No need to learn low-level CUDA programming.
- It’s very easy to massage CPU vs GPU numbers to look impressive. Read those ‘GPUs are awesome’ papers with care!
- In real life you have to consider data transfer times between GPU and CPU since these can dominate overall wall clock time with simple calculations such as those considered here. The more work you can do on the GPU, the better.
- My laptop’s GPU is nowhere near as good as I would have liked it to be. Almost 6 times slower than a Tesla C2050 (excluding data transfer) for elementwise double precision calculations. Data transfer times seem to about the same though.
Next time
In the next article in the series I’ll look at an element-wise calculation that really is worth doing on the GPU – even using the wimpy GPU in my laptop – and introduce the MATLAB function arrayfun.
Footnote
1 – MATLAB 2011a can’t create random numbers directly on the GPU. I have no doubt that we’ll be able to do this in future versions of MATLAB which will change the nature of this particular calculation somewhat. Then it will make sense to include the random number generation in the overall benchmark; transfer times to the GPU will be non-existant. In general, however, we’ll still come across plenty of situations where we’ll have a huge array in main memory that needs to be transferred to the GPU for further processing so what we learn here will not be wasted.
Hardware / Software used for the majority of this article
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit. I’m not using Linux because of the lack of official support for Optimus.
- MATLAB: 2011a with the parallel computing toolbox
Other GPU articles at Walking Randomly
- GPU Support in Mathematica, Maple, MATLAB and Maple Prime – See the various options available
- Insert new laptop to continue – My first attempt at using the GPU functionality in MATLAB
- NVIDIA lets down Linux laptop users – and how an open source project saves the day
Thanks to various people at The Mathworks for some useful discussions, advice and tutorials while creating this series of articles.
These days it seems that you can’t talk about scientific computing for more than 5 minutes without somone bringing up the topic of Graphics Processing Units (GPUs). Originally designed to make computer games look pretty, GPUs are massively parallel processors that promise to revolutionise the way we compute.
A brief glance at the specification of a typical laptop suggests why GPUs are the new hotness in numerical computing. Take my new one for instance, a Dell XPS L702X, which comes with a Quad-Core Intel i7 Sandybridge processor running at up to 2.9Ghz and an NVidia GT 555M with a whopping 144 CUDA cores. If you went back in time a few years and told a younger version of me that I’d soon own a 148 core laptop then young Mike would be stunned. He’d also be wondering ‘What’s the catch?’
Of course the main catch is that all processor cores are not created equally. Those 144 cores in my GPU are, individually, rather wimpy when compared to the ones in the Intel CPU. It’s the sheer quantity of them that makes the difference. The question at the forefront of my mind when I received my shiny new laptop was ‘Just how much of a difference?’
Now I’ve seen lots of articles that compare CPUs with GPUs and the GPUs always win…..by a lot! Dig down into the meat of these articles, however, and it turns out that things are not as simple as they seem. Roughly speaking, the abstract of some them could be summed up as ‘We took a serial algorithm written by a chimpanzee for an old, outdated CPU and spent 6 months parallelising and fine tuning it for a top of the line GPU. Our GPU version is up to 150 times faster!‘
Well it would be wouldn’t it?! In other news, Lewis Hamilton can drive his F1 supercar around Silverstone faster than my dad can in his clapped out 12 year old van! These articles are so prevalent that csgillespie.wordpress.com recently published an excellent article that summarised everything you should consider when evaluating them. What you do is take the claimed speed-up, apply a set of common sense questions and thus determine a realistic speedup. That factor of 150 can end up more like a factor of 8 once you think about it the right way.
That’s not to say that GPUs aren’t powerful or useful…it’s just that maybe they’ve been hyped up a bit too much!
So anyway, back to my laptop. It doesn’t have a top of the range GPU custom built for scientific computing, instead it has what Notebookcheck.net refers to as a fast middle class graphics card for laptops. It’s got all of the required bits though….144 cores and CUDA compute level 2.1 so surely it can whip the built in CPU even if it’s just by a little bit?
I decided to find out with a few randomly chosen tests. I wasn’t aiming for the kind of rigor that would lead to a peer reviewed journal but I did want to follow some basic rules at least
- I will only choose algorithms that have been optimised and parallelised for both the CPU and the GPU.
- I will release the source code of the tests so that they can be critised and repeated by others.
- I’ll do the whole thing in MATLAB using the new GPU functionality in the parallel computing toolbox. So, to repeat my calculations all you need to do is copy and paste some code. Using MATLAB also ensures that I’m using good quality code for both CPU and GPU.
The articles
This is the introduction to a set of articles about GPU computing on MATLAB using the parallel computing toolbox. Links to the rest of them are below and more will be added in the future.
- Elementwise operations on the GPU #1 – Basic commands using the PCT and how to write a ‘GPUs are awesome’ paper; no matter what results you get!
- Elementwise operations on the GPU #2 – A slightly more involved example showing a useful speed-up compared to the CPU. An introduction to MATLAB’s arrayfun
- Optimising a correlated asset calculation on MATLAB #1: Vectorisation on the CPU – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
- Optimising a correlated asset calculation on MATLAB #2: Using the GPU via the PCT – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
- Optimising a correlated asset calculation on MATLAB #3: Using the GPU via Jacket – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
External links of interest to MATLABers with an interest in GPUs
- The Parallel Computing Toolbox (PCT) – The Mathwork’s MATLAB add-on that gives you CUDA GPU support.
- Mike Gile’s MATLAB GPU Blog – from the University of Oxford
- Accelereyes – Developers of ‘Jacket’, an alternative to the parallel computing toolbox.
- A Mandelbrot Set on the GPU – Using the parallel computing toolbox to make pretty pictures…FAST!
- GP-you.org – A free CUDA-based GPU toolbox for MATLAB
- Matlab, CUDA and Me – Stu Blair gives various examples of calling CUDA kernels directly from MATLAB
I recently maxed out my credit card in order to treat myself to a shiny new Dell XPS L720X laptop that comes complete with Intel i7 sandy bridge processor and Nvidia GeForce GT 555M. The NVidia graphics card was one of the biggest selling points for me because I wanted to do some GPU work at home and on the train using both CUDA and OpenCL. I get asked about these technologies a lot by researchers at The University of Manchester and I wanted to beef up my experience levels.
I wanted this machine to be dual boot Windows 7 and Linux so, before I shelled out my hard-earned cash, I thought I would check that Nvidia’s Linux driver supported the GT 555M. A quick look at their official driver page confirmed that it did so I handed over the credit card. After all, if Nvidia themselves say that it is supported then you’d expect it to be supported right?

Wrong! Here’s my story.
I installed Ubuntu 11.04 from DVD without a hitch and updated all packages to the very latest versions. I then hopped over to NVidia’s website, got the driver (version 275.09.07) and installed it. I’ve gone through this process dozens of times on Desktop machines at work and wasn’t expecting any problems but boy did I get problems. After installing NVidia’s driver, the Dell simply would not boot into Linux. Not only that but it never seemed to fail in exactly the same place twice…the boot process would start just fine and then it would crash…seemingly at random. So, off to the forums I went where I quickly discovered that my system was not as supported as I originally thought.
You see, my laptop has two graphics systems on it: A relatively low-powered Intel one and the NVidia one. It also comes with some cool sounding technology called Optimus that helps save battery power on systems like mine. Rather than explain the details of Optimus, I’m just going to refer you to both Nvidia’s web page about it along with the Wikipedia page.
Here’s the kicker…Nvidia’s Linux driver does not support optimus, even though Optimus is Nvidia’s own technology. They even say that they don’t support it in the Additional Information tab. Furthermore, they have no plans to support it. Sadly, I didn’t even realise that my new laptop was an Optimus laptop until I tried to get the Nvidia drivers on it.
If only I had thought to myself ‘Well, Nvidia may say that they support the 555M but do they really mean it?’ If I mis-trusted the information given on the supported products page then perhaps then I would have read the further information tab and trawled the forums. I chose to trust Nvidia and assume that when a product was listed under ‘supported products’ then I didn’t need to worry. Well you live and learn I guess.
Project Bumblebee
One of the fantastic things about the Linux community is that even if you are let down by your hardware vendor then someone, somewhere may well come to your rescue. For Nvidia Optimus, that someone is Martin Juhl. Martin’s project, Bumblebee, brings Optimus support to Linux which is useful since it seems that Nvidia can’t be bothered!
Installation for Ubuntu users is easy. All you need to do is open up a terminal, type the following and follow the instructions to download and install both the Nvidia drivers along with bumblebee.
sudo apt-add-repository ppa:mj-casalogic/bumblebee sudo apt-get update && sudo apt-get install bumblebee
To run an application, glxgears for example, you just type the following at the command line
optirun glxgears
Sadly for me this didn’t work. All I got was the following
* Starting Bumblebee X server bumblebee _PS0 Enabling nVidia Card Succeded. [ OK ] * Stopping Bumblebee X server bumblebee _DSM Disabling nVidia Card Succeded. _PS3 Disabling nVidia Card Succeded.
Nothing else happened. I’d report it as a bug-report but it seems that someone with a very similar configuration to me has already done so and work is being done on it as we speak. Plenty of other people have reported success with bumblebee though and I am confident that I will be up and running soon. As soon as I am up and running I’ll owe the developer of bumblebee a beer!
Update 11th July: The bumblebee bug mentioned above has been fixed. I can now run apps via optirun. Not done much more than run glxgears though so far.